
afgeronde bouwjaren in de BAG generiek correct voorspellen
Introductie
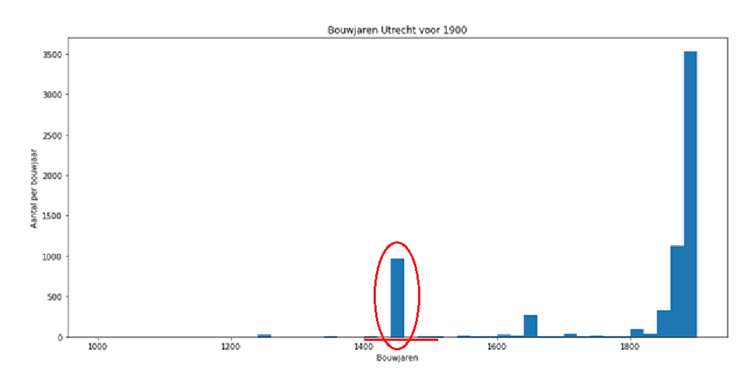
Gemeenten zijn sinds 2009 wettelijk verplicht de data in de BAG bij te houden. Echter is het in sommige gevallen moeilijk het precieze bouwjaar van oude panden te registreren. Dit kan komen doordat het bouwarchief in het verleden verloren is gegaan. Hierdoor waren brondocumenten niet aanwezig of binnen gestelde tijd te achterhalen toen de BAG geïmplementeerd werd. Om voor deze panden een bouwjaar in te vullen is met behulp van stadsarcheologen en historische kaarten een schatting gemaakt van het bouwjaar. Hierbij is bewust voor afgeronde bouwjaren gekozen. Bij gemeente Utrecht valt het bijvoorbeeld op dat bouwjaar 1450 bijna 1100 keer voorkomt in de BAG, terwijl er verder tussen 1400 en 1500 weinig panden gebouwd zijn.
Oplossing: een voorspelmodel
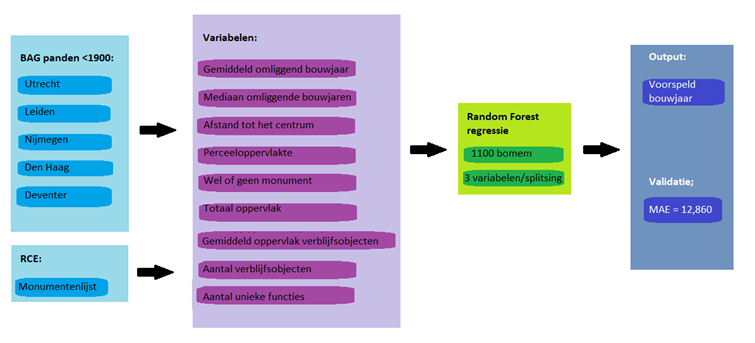
Om een betere schatting van de afgeronde bouwjaren te maken, kan er gebruik gemaakt worden van een machine learning model. Hierbij worden meerdere variabelen/kenmerken van een pand als input voor een machine learning model gebruikt en maakt dit model een schatting van het bouwjaar. Voor dit onderzoek is er een Random Forest regressie model getraind en een XG Boost regressie model. Om deze modellen te trainen moet eerst een analyse van de bouwjaren gemaakt worden. Aan de hand van deze analyse wordt een onderscheid tussen afgeronde bouwjaren en niet afgeronde bouwjaren gemaakt. De niet afgeronde bouwjaren worden op gedeeld in een train en test set. De verschillende modellen worden getraind aan de hand van de train set en de prestatie van het model wordt gevalideerd door het model de bouwjaren van de test set te laten voorspellen. Door de voorspellingen en de oorspronkelijke bouwjaren te vergelijken wordt een inzicht verkregen hoe goed het model de afgeronde bouwjaren kan voorspellen.
Toekomst: generalisatie van het voorspelmodel
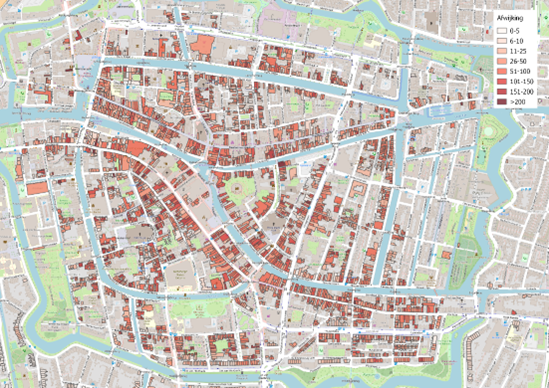
Om dit model breed inzetbaar te maken, met in de toekomst voor heel Nederland, moet het model gegeneraliseerd worden. Tijdens dit onderzoek is er onderzocht in hoeverre het mogelijk is een gegeneraliseerd model te maken. Hiervoor is gekeken naar 5 oude gemeenten: Utrecht, Nijmegen, Leiden, Den Haag en Deventer. Voor deze gemeenten presteert Random Forest regressie het beste. Er is een optimaal model bereikt bij 1100 bomen en 3 variabelen per splitsing. Bij de validatie van dit model kwam een gemiddelde fout van 12 jaar uit. De voorspellingen wijken dus gemiddeld maar 12 jaar af van de werkelijke waarden.
Vervolg stappen
Om het model te verbeteren kunnen de volgende zaken nog onderzocht worden:
- Onderzoek naar afgeronde bouwjaren;
- Verbreding door het toevoegen van nieuwe gemeenten;
- Verdieping door het toevoegen van geografische aspecten.