
Handgeschreven Aktes AI
De handgeschreven aktes van het Kadaster bevatten een schat aan historische informatie, maar zijn lastig doorzoekbaar en vaak moeilijk leesbaar. Dit onderzoek richt zich op twee vragen: hoe kunnen nieuwe technieken zoals Handwritten Text Recognition (HTR) helpen om deze aktes machineleesbaar te maken, en in hoeverre kunnen erfdienstbaarheden automatisch worden gedetecteerd? Door deze technieken in te zetten, kunnen we onderzoek efficiënter en minder tijdrovend maken.
Archiefonderzoek
Het Kadaster beheert een groot archief met oude aktes, waaronder zo’n 5 miljoen handgeschreven exemplaren uit de periode 1838 tot 1950. Deze aktes worden regelmatig gebruikt voor onderzoek, maar omdat ze niet doorzoekbaar zijn, moeten scans stuk voor stuk geopend en gelezen worden. Dit is tijdrovend en vraagt veel expertise, omdat het handschrift vaak lastig te ontcijferen is. Dit maakt het werken met deze aktes niet alleen arbeidsintensief, maar ook vermoeiend.

Om dit proces te verbeteren, zou het Kadaster deze handgeschreven aktes kunnen omzetten naar doorzoekbare tekstbestanden. Dit opent de deur naar nieuwe mogelijkheden, zoals het automatisch opsporen van specifieke kenmerken of passages binnen de aktes.
Erfdienstbaarheden
Eén soort onderzoek waarbij de handgeschreven aktes worden geraadpleegd is het Erfdienstbaarhedenonderzoek. Hierbij worden aktes gelezen tot aan het begin van de Kadastrale registratie. Elke akte waarin het betreffende perceel wordt genoemd, moet worden gecontroleerd op erfdienstbaarheden, zoals het recht van overpad.
Het onderzoek bestaat uit twee stappen: eerst worden alle relevante aktes verzameld, daarna worden deze gecontroleerd op erfdienstbaarheden. Dit is een tijdrovend proces, zeker omdat in oude aktes erfdienstbaarheden niet in aparte kopjes staan. In plaats daarvan moet de informatie uit de context van de tekst worden afgeleid.
Vraagstuk
Dit onderzoek richt zich op hoe nieuwe technieken het werkproces met handgeschreven aktes kunnen ondersteunen. De onderzoeksvragen zijn:
-
Kunnen de handgeschreven aktes machineleesbaar gemaakt worden?
De leesbaarheid van een akte hangt af van het handschrift en de scankwaliteit van de akte. Beide kunnen in sommige gevallen tegenvallen en het lastig maken de relevante informatie uit de akte te halen. Door de teksten machineleesbaar te maken kunnen de aktes enerzijds in een goed leesbare font getoond worden en anderzijds doorzocht worden op zoektermen.
-
Kunnen erfdienstbaarheden automatisch gedetecteerd worden in de doorzoekbare teksten?
Aktes bestaan soms uit tientallen pagina’s met tekst. Ergens daarin kan een erfdienstbaarheid omschreven staan. Is het mogelijk om de erfdienstbaarheid automatisch te extraheren?
Vraag 1: Handgeschreven tekstherkenning
Voor het halen van tekst uit scans bestaat de OCR techniek, Optical Character Recognition. Hiervan zijn veel standaardoplossingen beschikbaar, zoals tesseract of ABBYY finereader. Deze technieken onderzochten we al eerder in ons Akte OCR onderzoek, waarin scans na 1950 werden verwerkt. Anders dan de handgeschreven aktes waren deze met de typmachine opgeschreven.
Hoewel de resultaten voor de getypte akte goed bruikbaar waren, presteren deze technieken een stuk slechter bij de handgeschreven aktes. Dit komt doordat zulke tools vaak niet getraind zijn voor handschrift, maar ook doordat de scankwaliteit van de handgeschreven aktes lager is. Voor dit onderzoek is daarom gekozen om een subveld van OCR te onderzoeken, de HTR techniek, welke zich specifiek richt op handgeschreven teksten.
Dataverzameling
Om HTR optimaal te laten werken, is een hoogwaardige dataset essentieel. Het Kadaster maakt gebruik van een bestaande openbare dataset met duizenden overgetypte VOC- en notariële aktes. Deze is aangevuld met eigen annotaties om de modellen af te stemmen op onze specifieke archiefdata.
Bij de dataverzameling hebben we een diverse en representatieve set aktes samengesteld. Hierbij kozen we voor aktes uit verschillende decennia (de periode beslaat ruim 100 jaar) en uit verschillende bewaringen. Ook namen we aktes mee die opnieuw gescand zijn om te bepalen of de huidige scankwaliteit voldoende is of herhaling nodig is. Tot slot hebben we er op gelet op dat een deel van de aktes erfdienstbaarheden in de tekst bevatten, zodat we daar ook op kunnen testen voor de tweede deelvraag van het onderzoek.

Tijdens het annoteren van de verzamelde aktes zijn er drie dingen vastgelegd. Zo zijn van 771 scans de tekstregio’s en tekstregels aangegeven. De tekstregio’s laten ons weten wat er semantisch in de scan staat. Niet alleen kunnen we zodoende bijgevoegde tekeningen uit de scan halen, maar ook bepalen wat de rol van tekst is in de akte. Voorbeelden zijn paginanummers, volgnummers of paragrafen. Hoewel dat allemaal tekst is, is de functie zeer verschillend. Door de verschillen aan te geven kunnen we uiteindelijk het zoeken in aktes bijvoorbeeld beperken tot enkel de aktetekst. Gezien aktes achter elkaar door werden geschreven in de boekdelen kunnen aktes halverwege de pagina starten of eindigen. De volgnummer van de akte staat in de kantlijn en geeft aan welke akte het precies is, vooral wel zo handig als er meerdere aktes op één pagina staan.
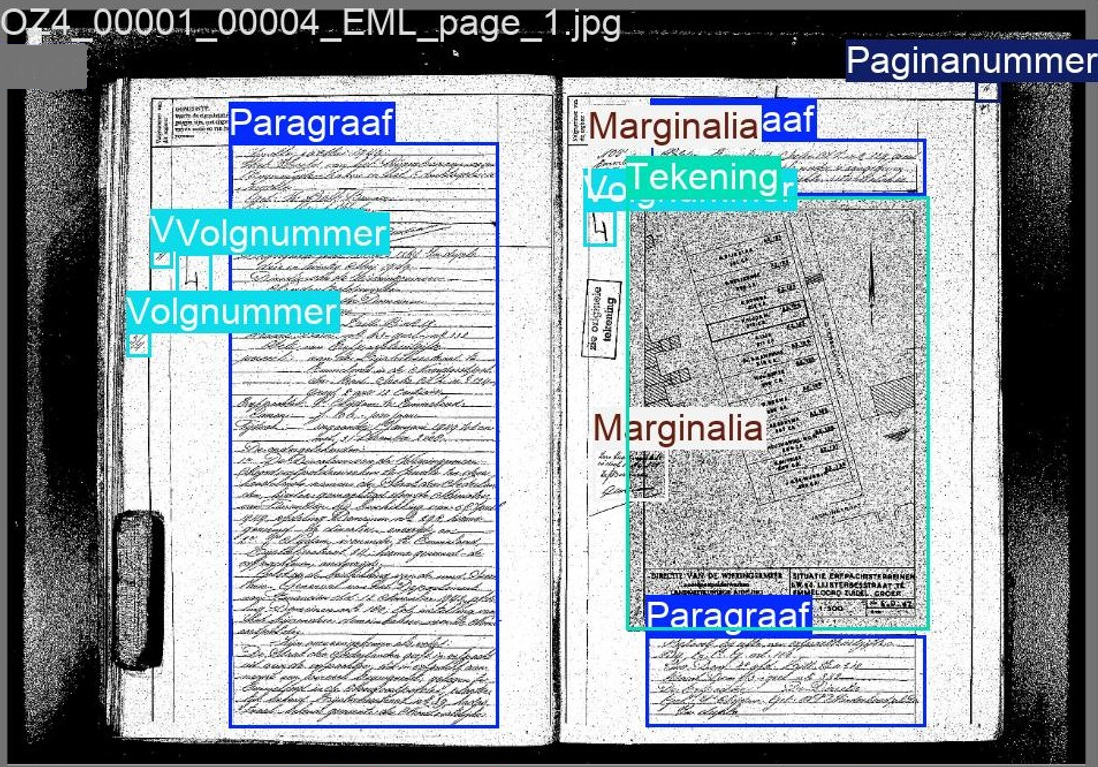
Het tweede wat is aangegeven, is waar de tekst precies is in de scan. Dit doen we met het aangeven van de tekstregels. Hoewel er op kleinere schaal (kassabonnetjes bijvoorbeeld) wel AI modellen zijn die de hele foto in één keer kunnen omzetten naar een lap tekst, zijn deze modellen nog niet krachtig genoeg zijn om dat voor een scan van een handgeschreven document te doen. Dat wordt eigenlijk altijd per tekstregel gedaan, waarvoor het dus nodig is om eerst deze tekstregels te vinden. Het is hiervoor mogelijk om de gewenste uitsnede al te annoteren, maar het is eenvoudiger en sneller om alleen een lijntje onder de tekstregel te zetten en achteraf met heuristieken een uitsnede te maken, hierbij gaat geen performance verloren.
Het derde wat tijdens de annotatie aangegeven wordt is het transcriberen van de tekst zelf. Dit was het meest tijdsintensieve deel, en kan ook alleen gedaan kon worden door domein experts die daadwerkelijk de scans goed kunnen lezen. Zij hebben uiteindelijk van 54 scans de volledige transcriptie geproduceerd.
Loghi tooling
Voor de HTR tooling hebben we de open-source Loghi van het KNAW als een startpunt gebruikt. In die tooling zijn reeds getrainde modellen beschikbaar die al gebruik maken van eerdergenoemde openbare dataset, al gebruiken we de tooling vooral voor de pipeline en werkmethode en trainen we de modellen opnieuw voor betere performance.
Eén van de problemen waar we tegenaan liepen is dat de data die gebruikt is om de standaardmodellen te creëren onvoldoende lijkt op onze data, met als gevolg dat de performance achter blijft. Wel kunnen we die data gebruiken om de modellen verder te trainen, maar dan moet de data verrijkt worden met augmentaties. Zodoende lijkt het trainingsmateriaal meer op de scans in onze archieven. Dit komt de performance van de modellen op onze data ten goede.

De Loghi tooling bestaat uit twee stappen om de scans om te zetten naar doorzoekbare tekst: 1) layout analyse en 2) tekstherkenning. Voor beide stappen zijn de openbare dataset met data augmentaties gebruikt.
Stap 1: Layout analyse
Om de tekst te kunnen herkennen, moet je eerst weten waar de tekst precies in de scan staat. De eerste stap is dus het lokaliseren van de tekstregels. Dit doen we met een segmentatie model. Hoe beter deze segmentatie gedaan wordt, hoe beter de tekst herkenning zal gaan. Het doel in deze stap is zou weinig mogelijk ruis, terwijl we complete tekstregels houden.

Stap 2: Tekstherkenning
Op basis van de gevonden tekstregels kunnen we uitsneden maken. Het is niet nodig om deze verder op te knippen in losse letters, de AI modellen kunnen een volledige zin in één keer omzetten. De uitsnede wordt dan als afbeelding door het HTR model gehaald.
Net als de vorige stap is het hiervoor nodig om een AI model te trainen op veel voorbeelden. Vanuit de gelabelde data zijn de tekstregels uitgesneden met daarbij de overgetypte tekst. Dit vormen paren van inputdata en ground truth, de gewenste uitkomst van het systeem. Dit stelt ons in staat om andere scans die niet handmatig overgeschreven zijn ook om te zetten naar tekst.

De tekstherkenningsstap valideren we op een aantal van de overgetypte Kadaster aktes, die geen onderdeel waren van de trainingsset. Over deze modellen wordt een voorspelling gedaan door de getrainde modellen, waarna we het verschil meten tussen de voorspelde tekst, en de gemaakte transcriptie. Elke letter die tussen beide verschilt is een fout.
We behalen hiermee een foutmarge van 5%. Dit maakt de teksten goed begrijpelijk en versnelt het onderzoek aanzienlijk. Onderzoekers kunnen nu sneller kerninformatie uit aktes halen en zijn minder afhankelijk van handmatige transcripties. Ook is het een gemiddelde en zijn er sommige aktes met goede scankwaliteit en leesbaar handschrift die bijna foutloos omgezet worden.
Vraag 2: Vinden van Erfdienstbaarheden
Eén van de toepassingen waarvoor de handgeschreven aktes geraadpleegd worden is het vinden van erfdienstbaarheden. In hoeverre kunnen we erfdienstbaarheden geautomatiseerd vinden?
Passages
Wanneer een erfdienstbaarhedenonderzoeken wordt uitgevoerd, worden de relevante passages uit de akte overgetypt die het erfdienstbaarheid omschrijven. Dit kan er één zijn per akte, of meerdere. Voor dit onderzoek hebben we 167 passages uit 162 aktes gepakt en met de getrainde AI modellen de tekst geëxtraheerd.
Tegenwoordig staan erfdienstbaarheden netjes onder een eigen kopje vermeld, maar dat was niet altijd zo. In dat geval moet het recht afgeleid worden aan de hand van de omschrijving in de aktetekst. Zo kunnen we een lijstje van zoektermen opstellen:
- Erfdienstbaarheid
- Servituut (ander woord voor erfdienstbaarheid)
- Recht van weg
- Recht van toegang
- Recht van overpad
- …
Simpelweg zoeken in de HTR resultaten werkt niet heel goed, omdat die fouten bevatten. Er worden dan misschien erfdienstbaarheden gevonden die er niet zijn, maar vooral erfdienstbaarheden gemist. Er zijn twee technieken waarmee we slimmer kunnen zoeken.
Techniek: Fuzzy search
De eerste onderzochte techniek is een “fuzzy search”. Hiermee staan we toe dat er verschillen tussen de zoekterm en de tekst mogen zitten. Bijvoorbeeld: “rech van vveg” kan gevonden worden als we op “recht van weg” zoeken. Dit werkt op basis van de Levenshteinafstand, waarbij elke toevoeging, wijziging en verwijdering van tekens wordt opgeteld. Door deze foutmarge afhankelijk te maken van de lengte van het woord, minimaliseren we foutpositieven zonder dat langere zoektermen worden gemist.
Fuzzy search presteert uitstekend op goed leesbare aktes. In deze gevallen wordt 98% van de relevante passages correct gevonden. Dit maakt het een effectieve techniek, vooral bij aktes met een hoge scankwaliteit en een leesbaar handschrift.

Techniek: zoeken in embeddings
De tweede techniek is het zoeken in embeddings. Hierbij wordt de tekst omgezet naar een vector van getallen, die de betekenis (semantiek) van de tekst vastlegt. Het voordeel hiervan is dat vergelijkbare woorden of zinnen toch bij elkaar worden gevonden. Bijvoorbeeld: “vennootschap” en “bedrijf” liggen in een embeddingsruimte dicht bij elkaar. Dit kan helpen bij het vinden van erfdienstbaarheden, zelfs als de exacte zoekterm niet aanwezig is.
De eerste tests met embeddings geven een succespercentage van 71%. Hoewel dit lager ligt dan bij fuzzy search, blijft het een interessante techniek. De lagere score is vermoedelijk te verklaren door de HTR-fouten en het gebruik van oud-Nederlands in de teksten. Toch kan deze techniek passages vinden die fuzzy search soms mist, vooral in aktes van lagere kwaliteit.
Conclusie
Het is mogelijk om in het HTR resultaat te zoeken op bepaalde zoekwoorden, daarmee worden indicaties gevonden voor erfdienstbaarheden. Wat na dit onderzoek nog niet kan zijn de details van de erfdienstbaarheden extraheren, bijvoorbeeld het heersende en dienende perceel. Een volledig erfdienstbaarhedenonderzoek bestaat tevens uit meer dan alleen het raadplegen van de aktetekst: het is een complex onderzoek waarbij een web van verschillende bronnen geraadpleegd worden. Automatisering van het hele proces is daardoor nog een paar stappen te ver.
Toch bieden de onderzochte technieken voldoende voordelen om hier mee verder te gaan. Zo helpen de HTR resultaten al erg met het lezen van de akten, wat daarmee minder vermoeiend wordt. Daarnaast helpen de indicatoren om snel naar de relevante sectie van een akte te gaan. Al met al zien we dit als een waardevolle ondersteuning bij de werkzaamheden. Daarnaast kan de techniek nog verder ingezet worden: zo kunnen we voorspellen welke scans voldoende leesbaar zijn en welke onvoldoende en dus opnieuw gescand moeten worden. Ook kan de datum van inschrijving geëxtraheerd worden.
Dit onderzoek laat zien dat HTR-technieken een enorme verbetering bieden bij het verwerken van handgeschreven aktes. Met een foutmarge van slechts 5% wordt het mogelijk om sneller en efficiënter door het historische archief te zoeken. Daarnaast maken slimme zoektechnieken zoals fuzzy search het vinden van erfdienstbaarheden een stuk eenvoudiger. In de toekomst kunnen verdere ontwikkelingen in AI en machine learning, zoals verbeterde taalmodellen en grotere datasets, de nauwkeurigheid en toepasbaarheid verder vergroten.