
Knowledge Graph voor datakwaliteit verbetering van data in originele bron
Introductie
De Knowledge graph is een relatief nieuw product van het Kadaster. Een Knowledge Graph is opgebouwd met linked data. Deze linked data heeft een triple store RDF structuur, wat betekent dat data niet meer bestaat uit tabellen met relaties, maar uit nodes met relaties. Deze nodes met relaties hebben de triple (drietallige) structuur subject-object-predicate. In onderstaande afbeelding is te zien hoe deze linked data is opgebouwd.
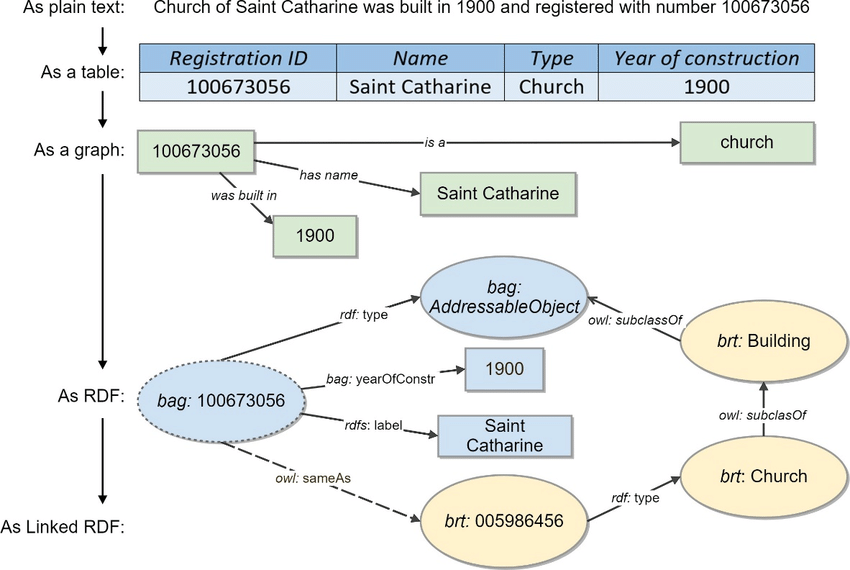
Deze Knowledge Graph is gebouwd door een groeiende vraag vanuit het Kadaster zelf en afnemers van Kadaster producten naar nieuwe inzichten in de beschikbare data. Doordat data nu gelinked is aan elkaar, wat eerder niet het geval was, kunnen er nieuwe inzichten verkregen worden uit de data van de geobasisregistraties die zijn opgenomen in de Knowledge Graph. Tijdens dit project is onderzocht wat er nou allemaal uit de Knowledge Graph te halen valt, en waar mogelijk in de toekomst naar gekeken kan worden.
Methodiek
Als opzet van dit onderzoek is een hoofdvraag geformuleerd:
- Hoe kan de kwaliteit van geselecteerde geo data, beschikbaar in en benaderd vanuit de knowledge graph als linked data, verbeterd worden, gelet op betrouwbaarheid van het verbeteringsproces?
Om deze hoofdvraag te beantwoorden is een drietal deelvragen opgesteld, welke in de aangegeven volgorde zijn beantwoord:
- Van welke geo data in de knowledge graph kan de kwaliteit, met welke reden, verbeterd worden?
- Hoe ziet het proces voor kwaliteitmeting eruit, op basis waarvan de data in deelvraag 1 beoordeeld wordt?
- Hoe kan het proces voor kwaliteitmeting van de data, beschreven in deelvraag 2, verbeterd worden, zodat de kwaliteidtsmeting zobetrouwbaar mogelijk is?
Als fundering voor het onderzoek is ISO 19157:2013 gehanteerd. Vanuit deze standaard is er gekeken naar volledigheid en semantische nauwkeurigheid van de data. Voor dit onderzoek is vooraf gekeken naar het data model van de Knowledge Graph om in te schatten welke data connecties mogelijk tot interessante resultaten kunnen leiden wanneer deze onderzocht worden. Op basis van dit vooronderzoek is besloten te kijken naar gebouwtypes (BRT), gebruiksdoelen (BAG) en bouwjaren (BAG). Er zijn nog andere mogelijkheden om te onderzoeken, maar deze zijn in dit onderzoek benoemd voor toekomstig onderzoek.
Resultaten uit onderzoek gebouwtypes (BRT) en gebruiksdoelen (BAG)
Voor dit onderdeel van het onderzoek is onderzocht of de Knowledge Graph kan ondersteunen in het vinden van gebouwen met een onlogisch verklaarbaar gebouwtype of gebruiksdoelen. Dit is gedaan door te controleren of bijvoorbeeld ieder gebouw met type ‘huizenblok’ het gebruiksdoel ‘woonfunctie’ heeft. Deze controle is uitgevoerd met behulp van een dictionary, waarvan hieronder een deel te zien is.

Tijdens het onderzoek bleek dat dit nog niet goed te controleren is met de Knowledge Graph, omdat het nog te onduidelijk is hoe gebouwen in de Knowledge Graph precies aan hun gebruiksdoel of gebouwtype komen. Als er bijvoorbeeld wordt gekeken naar het aantal gebouwen in de BRT met een gebouwtype, dan zijn dit er ongeveer drie miljoen. Echter, in de Knowledge Graph zijn er ruim 8 miljoen gebouwen met een gebouwtype. Wanneer deze gebouwtypes en gebruiksdoelen naast elkaar worden gelegd, blijkt dat ongeveer 85%, van de in totaal 8,1 miljoen gebouwen, geen logisch overeenkomend gebruiksdoel hebben, per gebouwtype. In onderstaande afbeelding is weergegeven voor de bovenlaag van de gebouwtypes, hoeveel gebouwen een onjuist overeenkomstig gebruiksdoel heeft.
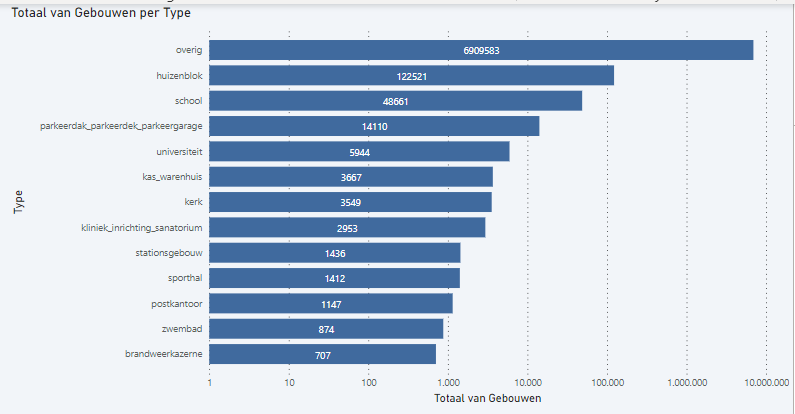
Op basis van dit gegeven zou het zo moeten zijn dat dus 85% van de gebouwen een verkeerd gebruiksdoel hebben, maar dat is hoogst onwaarschijnlijk. Het is dus opmerkelijk dat dit percentage zo hoog is. De oorzaak hiervan is nog onduidelijk, maar momenteel wordt vermoed dat dit komt door het feit dat gebouwen in de BAG en de BRT niet hetzelfde zijn. Er zijn namelijk verschillende normen voor wat een gebouw is in de respectievelijke basisregistraties. In de Knowledge Graph zijn deze gebouwen echter wel samengevoegd tot één entiteit. Mogelijk zit hier het probleem in.
Hiernaast komt er ook bij kijken dat beide basisregistraties afnemers dienen met ongelijke behoeften. Dit zorgt ervoor dat deze basisregistraties ook beide aan hun eigen eisen voldoen. Hierdoor zijn gebouwtypes in de BRT specifieker aangeduid dan gebruiksdoelen in de BAG. Dit leidt er ook toe dat deze gegevens lastig te vergelijken zijn of te gebruiken in een analyse.
Resultaten uit onderzoek gebouwtypes (BRT) en bouwjaren (BAG)
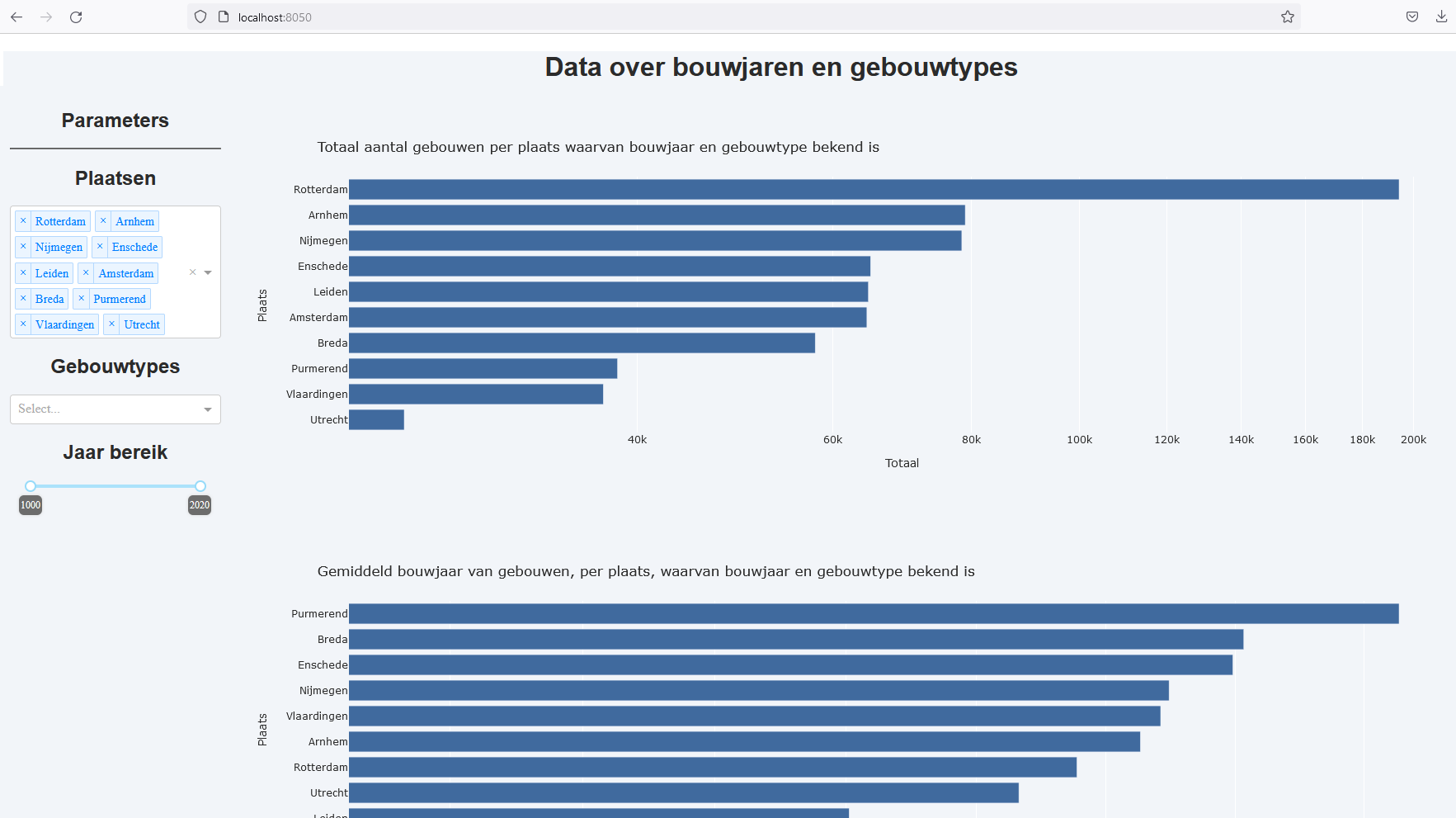
De gebouwtypes en bouwjaren zijn gegevens die ook meer kunnen vertellen over de data. Voor deze gegevens is vooral gekeken naar de het gemiddelde en de standaard deviatie van gebouwen, per plaats. Op basis van deze gegevens is bepaald waar mogelijk een grote hoeveelheid gebouwen met onjuiste bouwjaren zit. Via deze manier is gevonden dat er in Utrecht meerdere gebouwen zijn waarvan de exacte bouwjaren onbekend zijn. Om deze gebouwen een nauwkeurige schattig te kunnen geven kan mogelijk gebruik gemaakt worden van een soortgelijke toepassing als deze. Tevens is ook duidelijk geworden dat er in sommige gevallen een opmerkelijke spreiding is van de gebouwtypes.
Om de data over gebouwtypes en bouwjaren inzichtelijker te maken voor het Kadaster is een dashboard ontwikkeld in Dash. In onderstaande afbeelding is een deel van dit dashboard te zien. Hierin wordt het totaal van het aantal gebouwen weergegeven. Hiernaast is ook het gemiddelde, standaard deviatie en spreiding van de bouwjaren van gebouwen te zien door te scrollen op de pagina.
Conclusie
Uit de resultaten van het onderzoek bleek dat de Knowledge Graph nieuwe inzichten in de data kan bieden, maar dat hier ook kanttekeningen aan zitten. Deze nieuwe inzichten moeten namelijk wel kritisch bekeken, en met voorzorg benut worden. Bijvoorbeeld: zoals eerder benoemd is het momenteel onduidelijk wat in de Knowledge Graph nou een gebouw is, omdat dit gebouw bestaat uit gebouwen van verschillende bronnen, en deze bronnen hier hun eigen normen voor hebben. Wanneer deze betekenis duidelijker wordt, zal het ook meer betekenis kunnen geven aan de resultaten. Het zou wellicht ook interessant kunnen zijn om voor de Knowledge Graph te onderzoeken hoe bepaalde data attributen, oorspronkelijk uit verschillende bronnen, een meer universele definitie kunnen krijgen.
Op basis van het huidige onderzoek is ook gebleken dat de capaciteit voor bruikbare analyses met de Knowledge Graph nog beperkt is. Niet alle data beschikbaar in de originele bron is terug te vinden in de Knowledge Graph. Wellicht dat in de toekomst meer data onderzocht kan worden. Suggesties voor toekomstig onderzoek zouden bijvoorbeeld kunnen zijn:
- Terreinsoorten, waterdelen en wegdelen, afkomstig uit de BRT en BGT, beschikbaar in de Knowledge Graph.
- Perceeloppervlakte en vloeroppervlakte van panden beschikbaar in de Knowledge Graph.
- Analyseren van geometrische vormen in verschillende basisregistraties, beschikbaar in de Knowledge Graph.
- Analyse door toepassing van externe bronnen met de Knowledge Graph.