
Use Case: Locatiebepaling Appartementsrecht
Introductie
Meer dan 56% van de wereldbevolking woont in stedelijke gebieden, een aandeel dat naar verwachting zal toenemen tot 68% in 2050. Dit wereldwijde verstedelijkingsproces dwingt tot een efficiënt gebruik van de beschikbare ruimte en een toenemend aantal multifunctionele gebouwen, zoals kantoren, winkelcentra en woongebouwen. Nauwkeurig in kaart gebrachte locaties binnen deze multifunctionele eigendommen zijn nuttig voor verschillende organisaties in de huidige samenleving. Partijen zoals hulp- of bezorgdiensten hebben de informatie nodig om specifieke locaties zo snel mogelijk efficiënt te bereiken.
Momenteel zijn de meeste geografische informatiesystemen (GIS) zoals Apple Maps en Bing Maps nog steeds tweedimensionaal (2D). Driedimensionale (3D) systemen zoals Google Earth tonen alleen de contouren van gebouwen en hebben niet het detailniveau dat nodig is om plaatsen binnen een gebouw te lokaliseren. Er kunnen problemen ontstaan bij het uitzoeken van specifieke locaties, omdat namen en nummers inconsistent over een gebouw kunnen worden verdeeld, waardoor het onduidelijk is op welke verdieping en waar een eenheid zich bevindt. Dit kan lastig zijn voor bezorgers en zelfs levensbedreigend voor bewoners wanneer eerste hulp nodig is.
Gepubliceerd werk omtrent geocodering in de laatste decennia is beperkt tot dezelfde aantal methoden en vereist locatiereferentie informatie of is niet van toepassing op gebouwen met meerdere eenheden. Dit onderzoek heeft een generaliseerbare methode gerealiseerd om appartementsadressen toe te wijzen aan hun expliciete locaties zonder de binnenkant van een gebouw te kennen.
Methodiek
Het probleem wordt opgelost aan de hand van lineare interpolatie en gradient boosted decision trees (CatBoost). Daarnaast is het probleem opgesplitst in twee deelproblemen, (1) voorspelling van verdieping en (2) voorspelling van locatie op de verdieping. De deelproblemen worden afzonderlijk opgelost en geëvalueerd, aangezien beide stukjes informatie relevant zijn en als een van de twee taken een lagere betrouwbaarheid vertoont, lijdt de betrouwbaarheid van de andere taak er niet onder. Ten slotte worden de resultaten gecombineerd om de prestaties over het hele probleem te evalueren.
(1) In het geval van voorspellen van de verdieping, zullen de huisnummers van laag naar hoog over een geschat aantal verdiepingen worden geinterpoleerd. Verder zal een CatBoost regressie model worden getraind met de daadwerkelijke verdieping als label. Aangezien vloeren technisch, maar niet realistisch, oneindig groot kunnen zijn, kan het model niet worden gebonden aan een vast bereik van voorspellingslabels. Daarom kunnen de voorspellingen van het model ook onder de 0 komen. Deze waarden worden op 0 gezet. Bovendien zullen alle voorspelde labels worden afgerond, aangezien verdiepingen discrete waarden zijn.
(2) Wat betreft de locatievoorspelling op de verdieping, moet een generaliseerbare ruimte worden bepaald waarop appartementslocaties kunnen worden weergegeven, die consistent en toepasbaar moet zijn op andere gebouwen. Omdat elk gebouw een andere vorm heeft, kunnen de plattegrondvormen aanzienlijk variëren en is de 2D-weergave van een verdieping daarom ongeschikt als algemene ruimte om adressen op te plaatsen. Om een consistente ruimte voor appartementslocaties te garanderen, wordt ervan uitgegaan dat elk appartement op een manier direct verbonden is met de buitenwereld (bijvoorbeeld door een deur of raam). Hierdoor kan de omtrek van het gebouw een 1-dimensionale ruimte vertegenwoordigen die in lengte kan variëren, maar de relatieve afstand van een appartement tot een consistent startpunt zorgt voor generaliseerbaarheid over gebouwen. De enige gebouwtypen die problemen kunnen opleveren, zijn gebouwen met meerdere verbindingen naar de buitenwereld, bijvoorbeeld gebouwen met appartementen die alleen zijn verbonden met een binnenplaats. Deze gebouwen worden handmatig uit de dataset verwijderd.
Verder zal er een consistente startplaats op de gebouw omtrek moeten worden bepaald. Net als voorheen moet de startplaats consistent zijn over verschillende gebouwen en generaliseerbaar zijn in de zin dat deze kan worden geïdentificeerd zonder de binnenkant van het gebouw te weten. De hoek van het gebouw aan de lage kant van de nummeringsrichting van de direct aangrenzende openbareruimte zal daarom als startpunt dienen.
Om de relatieve afstand tot het startpunt voor beide zijden van het gebouw consistent te houden, wordt de omtrek in tweeën gesplitst. De appartementen die aan de kant van de aangrenzende openbareruimte liggen krijgen, met de klok mee,een positieve waarde tussen 0 en 100. De appartementen aan de andere kant van het gebouw krijgen, tegen de klok in, een waarde tussen 0 en -100. Op deze manier weerspiegelt de grootte van de waarde de relatieve afstand tot het startpunt voor beide zijden van het gebouw en weerspiegelt de positiviteit/negativiteit de zijde waar het appartement zich bevindt.
De afbeelding hieronder toont een visualisatie van de vastgestelde ‘echte’ locatie voor een kleine set appartementen. De groene hoek vertegenwoordigt het startpunt, de blauwe lijn vertegenwoordigt de ruimte die de richting van de aangrenzende straat met de klok mee volgt, de rode lijn vertegenwoordigt de tegenovergestelde richting, en de gele stippen vertegenwoordigen de dichtstbijzijnde locatie voor een appartement op omtrek van het gebouw.
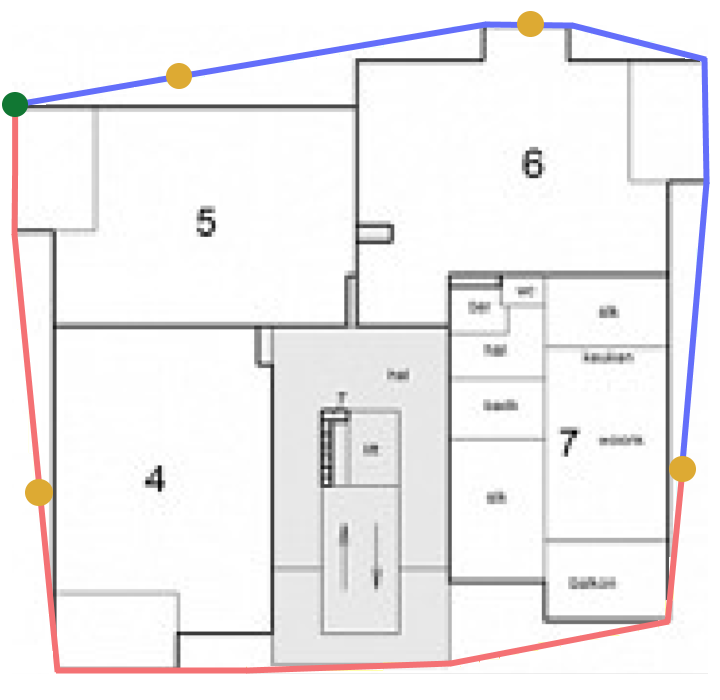
Kwa interpolatie worden de huisnummers afwisselend met de klok mee en tegen de klok in rond de omtrek van het gebouw geplaatst. In tegenstelling tot de verdiepingsvoorspellingen, staat het bereik van voorspellingslabels voor locaties op de vloer vast. Om een model te realiseren dat geen labels buiten het bereik van -100 tot 100 voorspelt, zal een CatBoost-model worden getraind dat is gebonden aan deze reeks uitkomsten. Dit kan worden bereikt door een binaire CatBoost classifier te trainen met een cross-entropy loss functie. Dit werkt op dezelfde manier als een logistisch regressiemodel, waarbij alleen een reeks labels tussen de 0 en 1 mogelijk is. Via deze methode zal een model getrained worden dat twee waardes voorspelt:
- De afstand tot het startpunt (0 tot 100) wordt genormaliseerd om binnen het toegestane bereik van 0 en 1 te passen en geeft de kans weer dat een appartement verder op de omtrek van het gebouw ligt.
- De kans dat het appartement aan de straatkant ligt. Een output van 1 vertegenwoordigt de straatkant en een output van 0 vertegenwoordigt de andere kant.
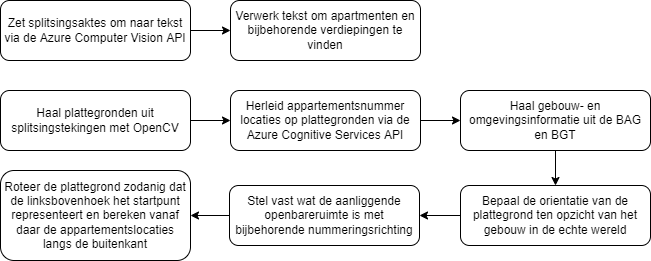
De labels voor de CatBoost modellen worden automatisch uit splitsingsaktes/tekingen gehaald en de features worden gevormd aan de hand van openbaar beschikbare gebouw- en adresinformatie uit de Basisregistratie Adressen en Gebouwen (BAG). De afbeelding hieronder geeft een indicatie van de stappen die genomen worden tijdens de automatische verwerking van de splitsingsdocumenten naar labels.
Resultaten
Verdieping voorspelling
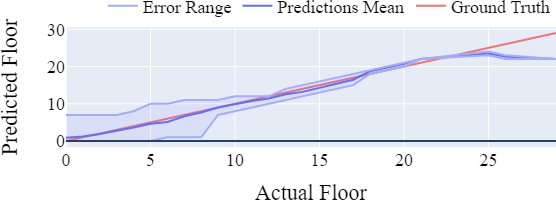
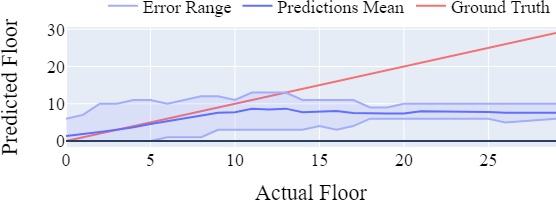
De grafieken hieronder (links interpolatie, rechts CatBoost) laten zien dat beide methodes vergelijkbaar presteren bij verdiepingen lager dan 10. Bij hogere gebouwen leent interpolatie zich tot beter resultaten.
Locatie op de verdieping voorspelling
De grafieken hieronder (links interpolatie, rechts CatBoost) laten zien dat CatBoost beter in staat is om de afstand tot het startpunt te voorspellen.
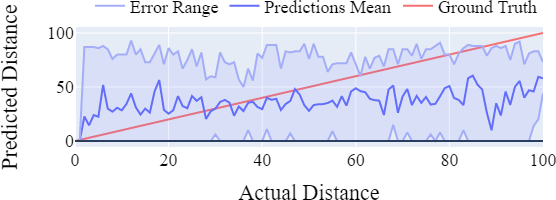
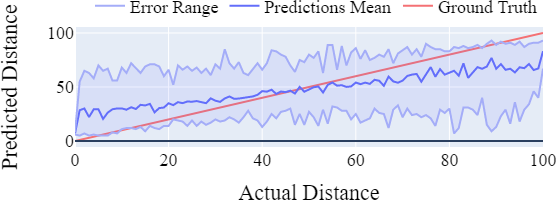
Verder is CatBoost ook beter in het voorspellen aan welke zijde van het gebouw een appertement ligt.
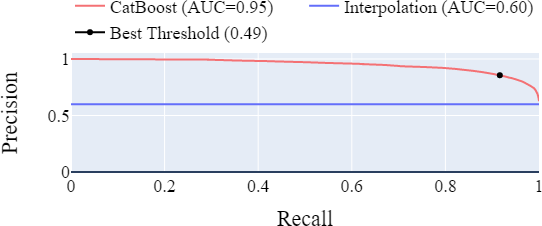
Gecombineerd
Om een indicatie te geven van de gecombineerde model prestaties wordt de positionele nauwkeurigheid berekend, deze weerspiegelt de afstand van het voorspelde punt tot de correct locatie in meters. De verticale nauwkeurigheid wordt berekend als het verschil tussen de voorspelde en correcte verdieping vermenigvuldigd met 3 (gemidelde Nederlandse verdiepingshoogte 2.6m + verdiepingsdikte 0.4m).
De horizontale nauwkeurigheid wordt berekend door het voorspelde punt op de omtrek van het gebouw terug in het gebouw te plaatsen. Door het punt richting zijn mediale as te schuiven, zoals te zien is op de afbeelding hieronder. Daarna wordt de afstand tot het originele punt op de plattegrond berekend via rijksdriehoekcoordinaten.

De grafiek hieronder representeerd de positionele nauwkeurigheid relatief aan de grootte van het bijbehorende gebouw. Hieruit blijkt dat alleen bij kleine gebouwen de relatieve foutmarge iets groter is, maar over het algemeen lijden de modellen niet significant onder verschillende gebouw groottes. CatBoost geeft de beste resultaten voor de gecombineerde modellen met een mediaan positionele fout van 14 meter.
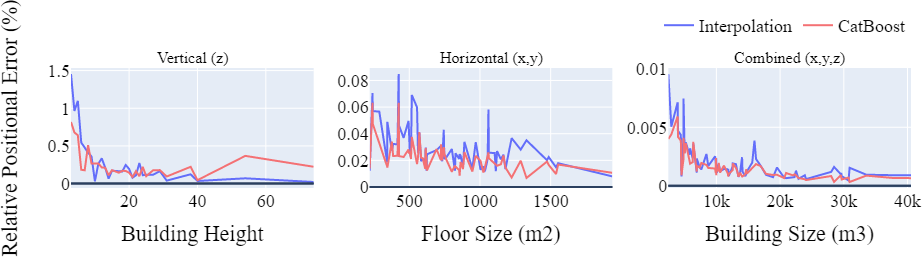
Conclusie
Het doel van dit onderzoek was om een generaliseerbare methode te realiseren om appartementsadressen toe te wijzen aan hun expliciete locaties zonder de binnenkant van het gebouw te weten. De resultaten laten zien dat gradient boosted decision trees niet significant beter presteren dan lineaire interpolatie in de context van verticale locatievoorspellingen (verdiepingen). Echter, voor horizontale (locatie op de vloer) en gecombineerde locatievoorspellingen laten de gradient boosted decision trees een significant betere positionele nauwkeurigheid zien. De meest invloedrijke variabelen voor het model waren het (gestandaardiseerde) huisnummer, het aantal verdiepingen in het gebouw (schatting) en de oppervlakte van het appartement. Het best gevonden resultaat had een afwijking minder dan een meter.
Toekomstig werk wordt geadviseerd om een manier te onderzoeken om de representatie toe te passen op gebouwen met meerdere buitenkanten, evenals om een grotere, meer diverse dataset te gebruiken (aangezien voor dit onderzoek een dataset van slechts 80 splitsingsaktes is gebruikt) en een complexer model toe te passen dat verbanden tussen features kan leren.