Kadaster’s Metadata Infrastructure: In Support of the ‘Platform of the Future’
System Architecture
The baseline architecture defined in the product document provides a foundational or as-is view of the system architecture. The design problems, requirements and fit criteria presented in the first section of this chapter provide directions for change in designing the system architecture. The following section presents this architecture. Rather than presenting this design in architectural layers as done with the baseline architecture, the architectural viewpoints presented highlight how the treatment design meets the requirements defined; both for the system as a whole and for the sub-systems where relevant. In doing so, the focus is on highlighting those elements of the design that are introduced to solve existing challenges and discussing these approaches in detail. As such, this subsection is organised around the requirements defined for the system architecture, discussing each design addressing these requirements in turn. In presenting the treatment design, there are a few notable issues. Perhaps as a consequence of the fractured nature of the baseline infrastructure, the baseline architecture was presented as three largely distinct sub-systems. In presenting the treatment design, the focus is on designing the system as a whole so that the application and technology architectures can be generically applied, with only minor changes made to accommodate sub-system-specific features and applications. As an extension of this, not all baseline viewpoints have been remodelled. Where these have not been redesigned, it can be assumed that changes to this sub-system are made at the system level and the sub-system conforms to this model.
Metadata Ownership and Stewardship
In the context of data governance, concepts of data ownership and stewardship are common, if not always explicitly present in an organisational structure. The data owner is accountable for the creation and maintenance of a data asset and is responsible for the definition of business rules, policies and frameworks as well as standards for data. These individuals are also usually responsible for approving data usage and access rights. Stewards, on the other hand, are usually subject matter or domain experts responsible for the operationalisation of rules and procedures defined by the owner. These individuals also carry out monitoring, cleansing and documentation tasks; providing support to users of the data.
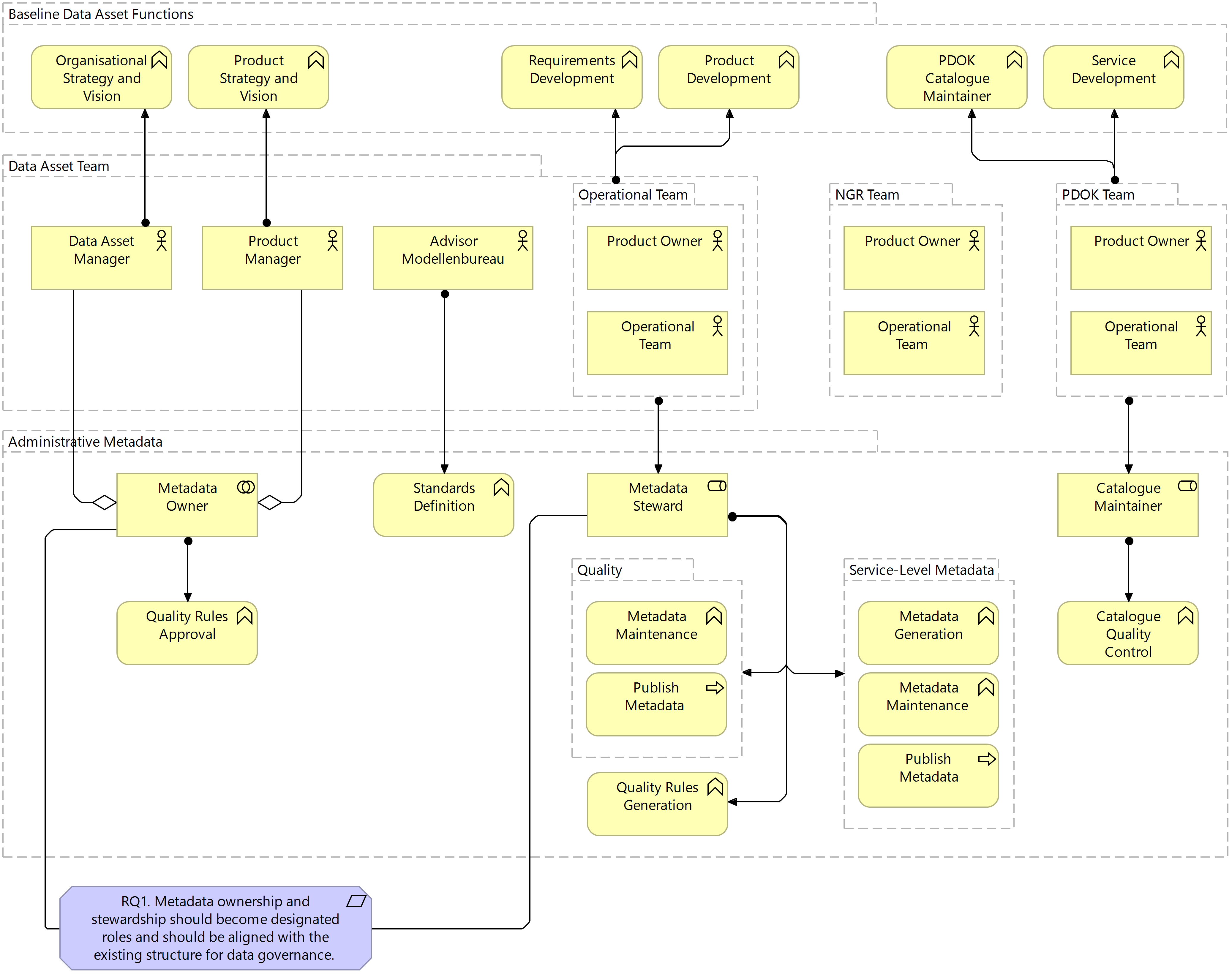
Within the boundaries of these two roles, responsibility for the generation and maintenance of metadata generally falls into the remit of the data stewards. Although the roles of data owner and data steward are not explicitly defined in the Kadaster context, the Operational Teams are broadly assigned the role of data steward and, as such, are also generally responsible for the generation and maintenance of metadata. The quality and inefficiency issues identified during this project, however, call for a strengthening of the governance structure for metadata specifically and, as such, the role of metadata owner and steward has been explicitly defined in the business layer of the target architecture. The following figure illustrates the assignment of these roles at the system level; addressing the first requirement defined for the system.
Figure 7.3 Target Business Layer: Metadata Infrastructure System
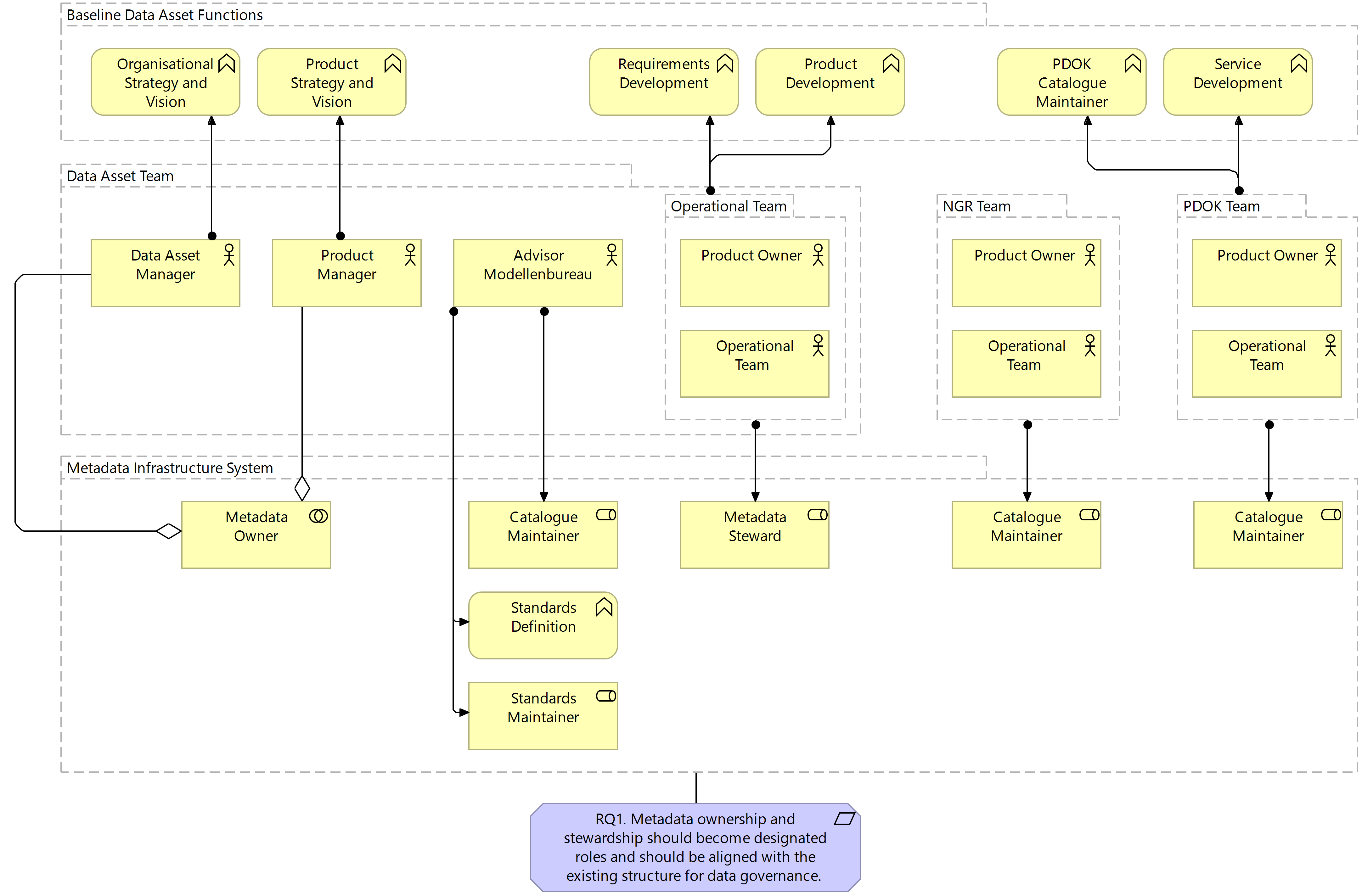
As the Team responsible for the daily operationalisation of standards, frameworks and policies related to data through the development of requirements and products, the assignment of Metadata Steward to the Operational Team is a logical one. Where stronger frameworks and clear standards are defined for metadata, the Operational Teams are well-positioned to implement this as part of their existing working structures. The definition of these policies and frameworks for metadata, as well as the accountability for ensuring that these are implemented well, fall largely into the remit of the Product Manager as the Metadata Owner. This ownership role is carried out in collaboration with the Data Asset Manager because, while the Product Manager is focused on ensuring the success of data products associated with a single asset, Data Asset Managers are responsible for ensuring that each asset is following the organisational policies and frameworks laid out. This collaboration between Data Asset Manager and Product Manager is more relevant in some sub-systems than in others as the following figures will highlight the role of the Modellenbureau in this system architecture should not be understated. As the body primarily responsible for ensuring the visibility of internal and external standards, the Modellenbureau supports Metadata Owners in achieving standards compliance.
Figure 7.4 Target Business Layer: Dataset Descriptions
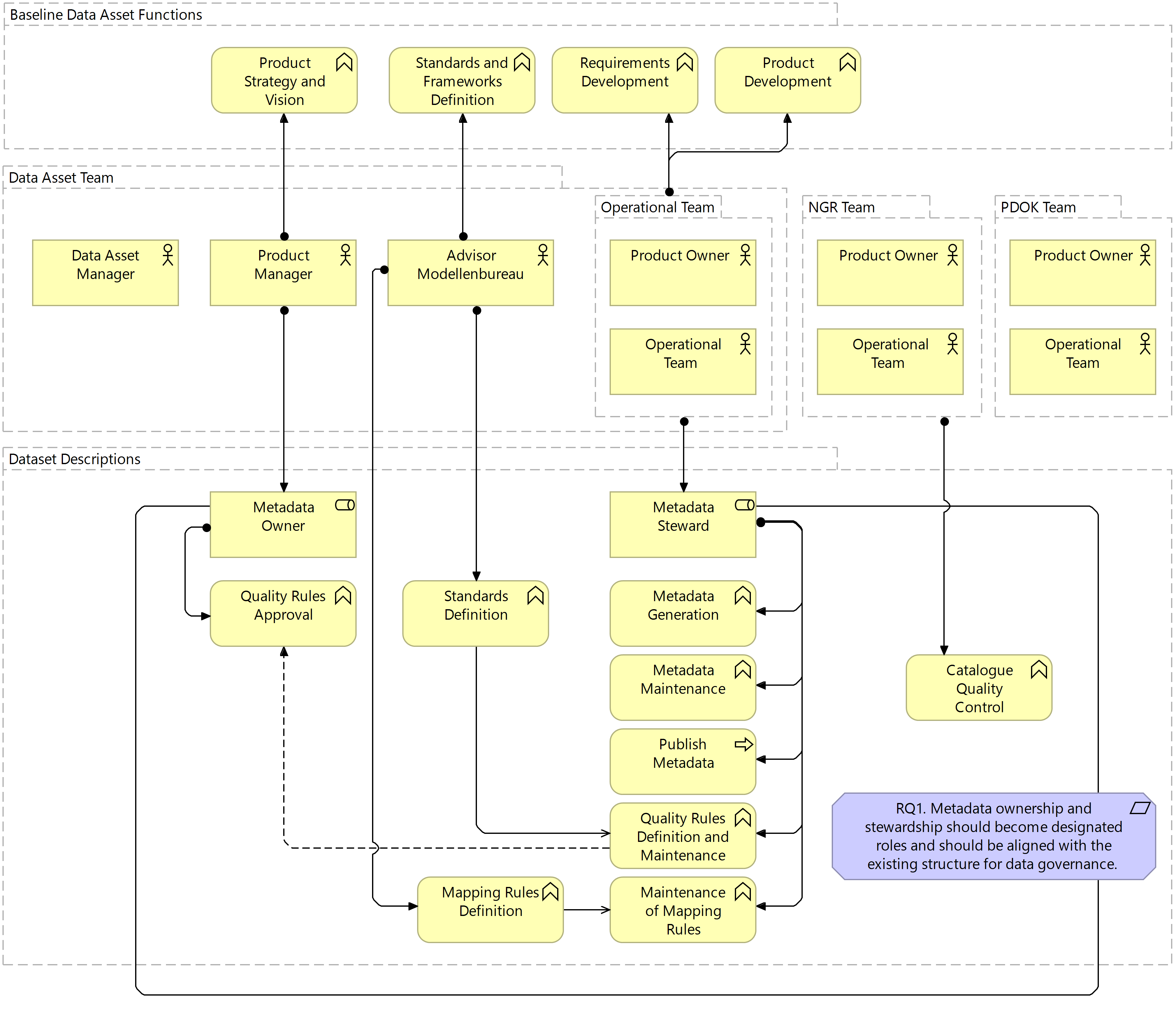
For the dataset descriptions sub-system, stewardship is assigned to the Operational Team with ownership assigned to the Product Manager. The lack of collaboration with the Data Asset Manager in this system is due to the fact that dataset descriptions are generated for each data product made available rather than for the data asset as a whole. Of greater influence in this system is the role of the Modellenbureau in defining the standards to which dataset descriptions should conform based on the requirements of various publication outlets. Based on these standards, the quality rules for dataset descriptions are defined by the Operational Team and approved by the Product Manager. With the vision that metadata should not be generated for a specific publication outlet, in this case for NGR alone, mapping rules between various standards and vocabularies relevant to dataset descriptions are also defined. These mapping rules support the automatic transformation of ISO19115 metadata, required for NGR publication, to DCAT, SDO and others, required for search engine indexing and metadata catalogue interoperability. The NGR team is then responsible for ensuring that the resulting metadata is of a high enough quality for publication in the metadata catalogue. The assignment of ownership and stewardship in this case supports less involvement of external actors such as NGR in the governance and quality of dataset descriptions.
Figure 7.5 Target Business Layer: Structural Metadata
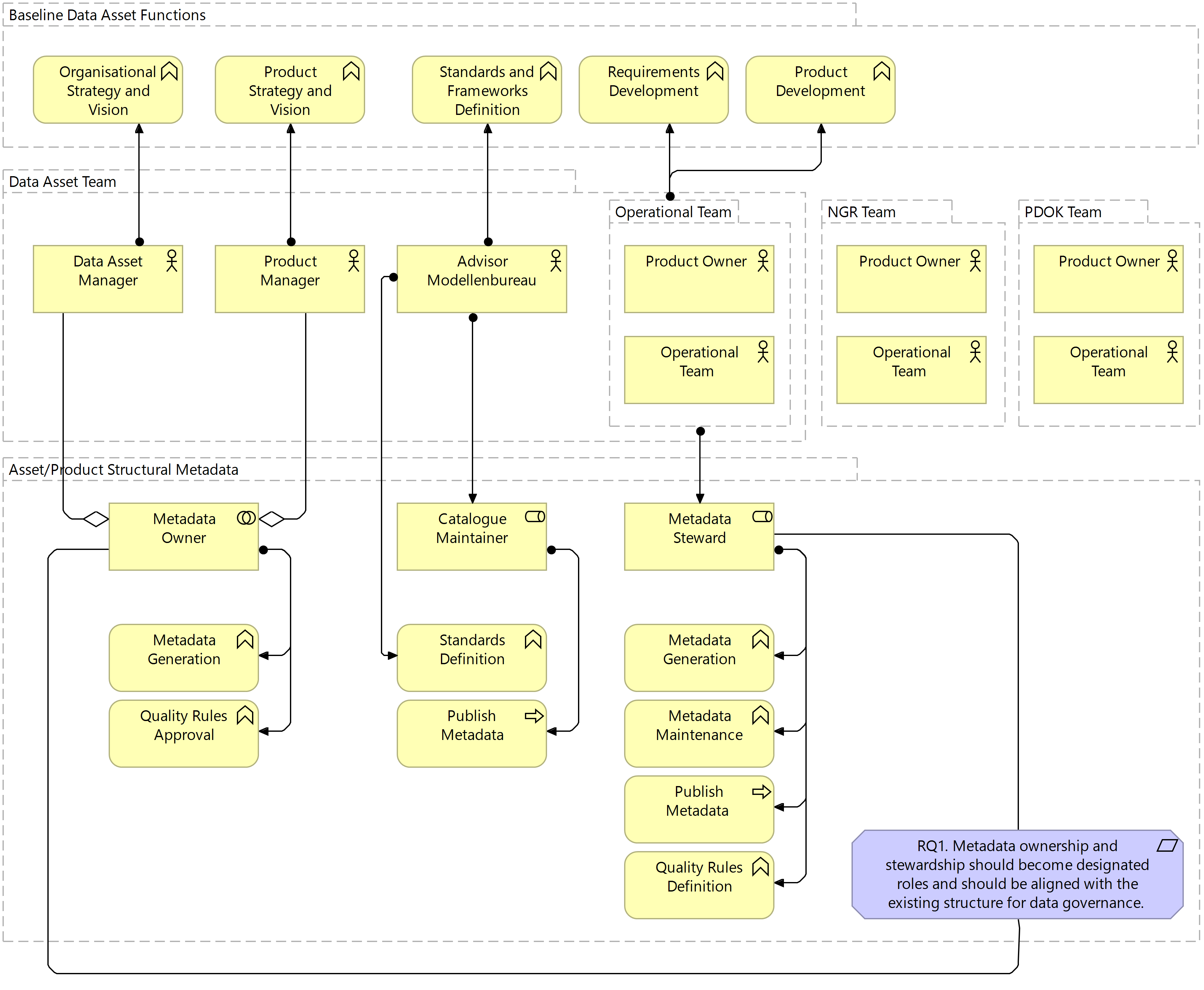
In line with the system business architecture presented above, the Operational Team is assigned the role of Metadata Steward and the Product Manager in collaboration with the Data Asset Manager the role of Metadata Owner. Here, the Modellenbureau also play a role in defining the relevant standards for the structural metadata but also as the catalogue maintainer and publisher of concept lists for the Kadaster Catalogus. The standards defined by the Modellenbureau are directly influential on the definition of the quality rules defined by the Operational Team and those approved by the metadata owners. The explicit inclusion of the Data Asset Manager as Metadata Owner in this system is based on the importance that the generation and publication of structural metadata has from an organisational perspective. The final accountability for ensuring that the content of this metadata is aligned with organisational policy falls with the Data Asset Manager and, therefore, requires the collaboration between this individual and the Product Manager responsible for policies and frameworks internal to the data asset teams.
Figure 7.6 Target Business Layer: Administrative Metadata
Although the business layer of this sub-system is aligned with the system overall, there is some nuance in the governance of the types of metadata defined within the scope of this system. Firstly, while the Operational Team is designed to be generally responsible for the creation, maintenance and publication of all metadata associated with an asset, the quality information offers an exception to this rule because the metadata itself is generated by the external owners of the data, the Dutch municipalities. This is a process which cannot be altered and, therefore, remains as such in the target architecture. Secondly, all metadata activities associated with service-level metadata fall now completely within the remit of the Operational Teams as stewards. The publication of this data happens not in the PDOK service catalogue but rather in the metadata repository, the design for which is discussed later in this chapter. The PDOK team, in being the catalogue maintainer is responsible for the retrieval of this information and for controlling the quality of this information. The definition of quality rules carried out by the metadata stewards should take into account the quality requirements of the catalogues in question.
Publication Outlet Landscape
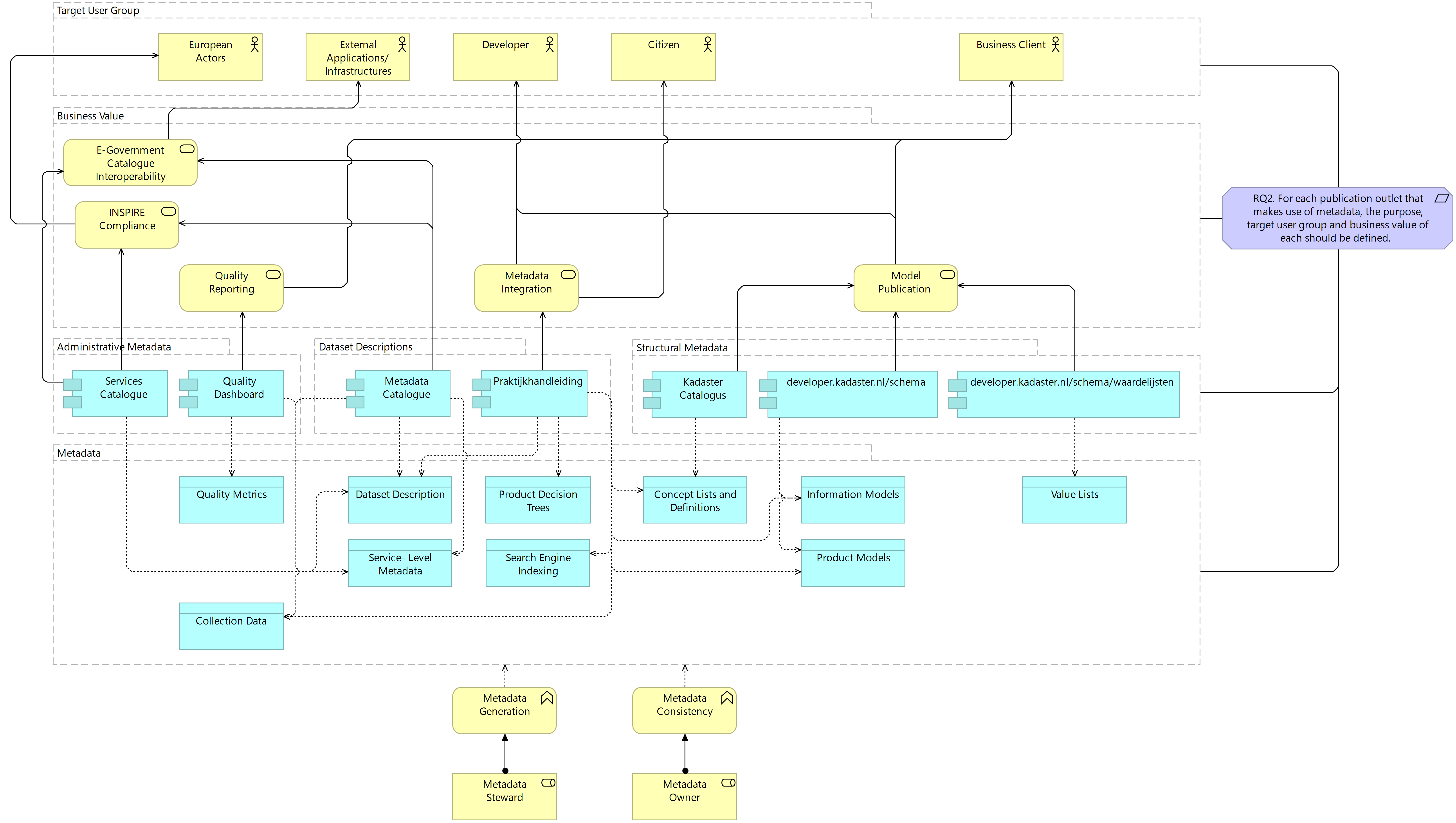
One of the key deterministic factors in the baseline architecture is the tight coupling between metadata generation activities and the requirements of publication outlets. Indeed, much of the metadata being currently generated in the Kadaster context is solely in conformance with a set of publication outlet requirements rather than in service of plurality and richness of metadata for the end user and, because these outlets generally serve a particular sub-system, create metadata siloes lacking interoperability between sub-systems. Having identified this tendency towards siloed metadata, however, the existence and requirements of these publication outlets do generally serve a particular user need. It would be too simplistic, therefore, to simply remove these outlets from the metadata infrastructure in service of one central metadata catalogue. What is required, rather, is an overview of which business cases metadata serve in support of two related goals. Firstly, identifying the business cases that outlets serve supports the identification of overlap and potential redundancy of similar applications. Simplifying the landscape where this occurs reduces the complexity for end users and reduces the costs of the infrastructure. Secondly, identifying where business cases overlap but do not necessarily result in redundancy may support the identification of cases where existing metadata could be reused in service of outlet requirements. Reusing existing metadata supports increased efficiency and reduced infrastructure costs. The following figure presents the treatment design in service of the second system requirement.
For each of the publication outlets identified in the problem context and baseline architectures, a business case has been defined in the above treatment design. The metadata steward is assigned in this architecture to the generation of specific types of metadata and the metadata owner to ensure that there is consistency in the quality and availability of metadata across outlets for a given asset. In service of requirement 2, this architecture itself should be maintained by the metadata stewards and where inconsistencies or redundancy in publication arise across data assets, Data Asset Managers for a single data asset should be solving these in collaboration with the Data Asset Managers for other data assets. In this way, a standardised architecture for publication is worked towards with each data asset team striving to improve the quality of their metadata in each publication. In the current state of the metadata infrastructure, no redundancy is identified but the overlap of metadata types is clear; suggesting a clear need to increase the reuse of metadata for different publication outlets. This requires the generation of metadata according to broader requirements than those defined by a single publication outlet.
Figure 7.7 Target Business Architecture: Business Case Management
Standards Management
One of the key issues identified by stakeholders in the problem context analysis is the lack of visibility of required and/or useful standards for the publication of metadata of all types. The problem context analysis also identified that the Modellenbureau is generally seen as responsible for defining the usage of these standards within the organisation. While this responsibility is also recognised and taken up by the Modellenbureau to a certain degree, there remains a lack of visibility of these standards; particularly for non-structural metadata standards. This need for better management and visibility of standards for metadata led to the definition of the third system requirement.
In the fulfilment of the third system requirement and the principle for standards identification and management, the following architectural viewpoints offer a business architecture for the identification of new standards and vocabularies across all sub-systems as well as a business architecture for the inclusion of these new standards and vocabularies into an existing list of standards. The associated application and technology layer supports the definition of use cases for existing standards and vocabularies, improving the understanding of where standards and vocabularies should be applied in service of a particular business case or user context. In addressing the third system requirement, the following models also design architecture supporting the fulfilment of the sixth, seventh and ninth system requirements; highlighting the holistic approach taken in designing the target architecture for the system. The latter requirements will, however, be discussed in more detail in the following subsections of this chapter.
The following architecture designates the Modellenbureau as responsible for the identification and then the maintenance of standards and vocabularies for metadata. This is not a large departure from the existing scope of the Modellenbureau but it does require that stronger management processes are designed to support the identification of new standards and vocabularies and, where necessary, mappings between these to support better compliance to standards and increased reuse of existing metadata.
Figure 7.8. Target Business Layer: Current Standards Management
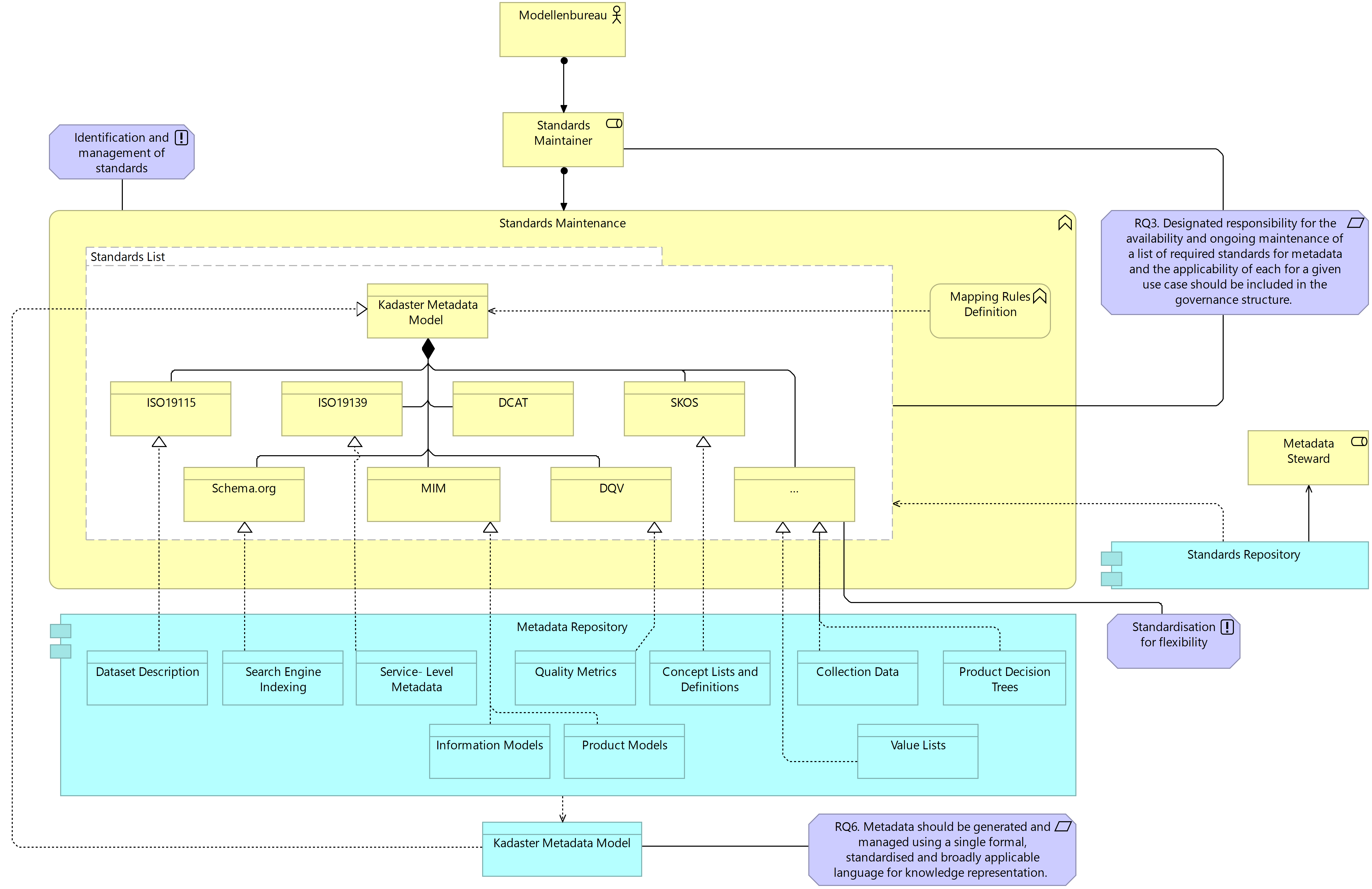
The standards and vocabularies presented here are but a handful of those likely already known and implemented in the Kadaster context. This list does, however, support a representation of metadata for the full range of use cases identified by the baseline architecture as illustrated in the application layer above. The relation between the list of standards and metadata types used in various applications is important to maintain; responsibility for which is designated to the Modellenbureau in the treatment design. The list of known standards and vocabularies for metadata representation, as well as the use cases these serve, should be stored in a standards repository. In the baseline architecture, this is done in a Wiki environment maintained by the Modellenbureau and could simply be reused going forward with an expanded list of standards and vocabularies. The only requirement herein is to ensure that this list is communicated by the Modellenbureau to the Operational Teams as metadata stewards for a given data asset.
It is inevitable, particularly considering that the scope of the metadata infrastructure defined in this project is smaller than that of the organisation itself, that new standards and vocabularies will be to be introduced. In addressing the seventh system requirement, the addition of a new standard or vocabulary requires that the new addition conforms to the FAIR vocabulary rules (see Table 7.15) to improve the interoperability between different types of metadata and, therefore, between different sub-systems. Where a given addition does not conform to these rules initially, this is easily addressed by the Modellenbureau in the Kadaster context. It is, therefore, unlikely that an addition does not get included based on these rules.
Table 7.15 FAIR Vocabulary Rules
| Rule No. | Description |
|---|---|
| 1 | Determine the governance arrangements and custodian of the legacy vocabulary |
| 2 | Verify that the legacy-vocabulary license allows repurposing and agree on the license for the FAIR vocabulary |
| 3 | Check term and definition completeness and consistency in the legacy vocabulary |
| 4 | Establish a traceable maintenance environment for the FAIR vocabulary content |
| 5 | Assign a unique and persistent identifier to (a) the vocabulary and (b) each term in the vocabulary |
| 6 | Create machine-readable representations of the vocabulary terms |
| 7 | Add vocabulary metadata |
| 8 | Register the vocabulary |
| 9 | Make the vocabulary accessible for humans and machines |
| 10 | Implement a process for maintaining the FAIR vocabulary |
Source: FAIR Vocabulary Rules, retrieved from: https://fairvocabularies.github.io/makeVocabularyFAIR
Figure 7.9 Target Business Layer: New Standards Identification and Management
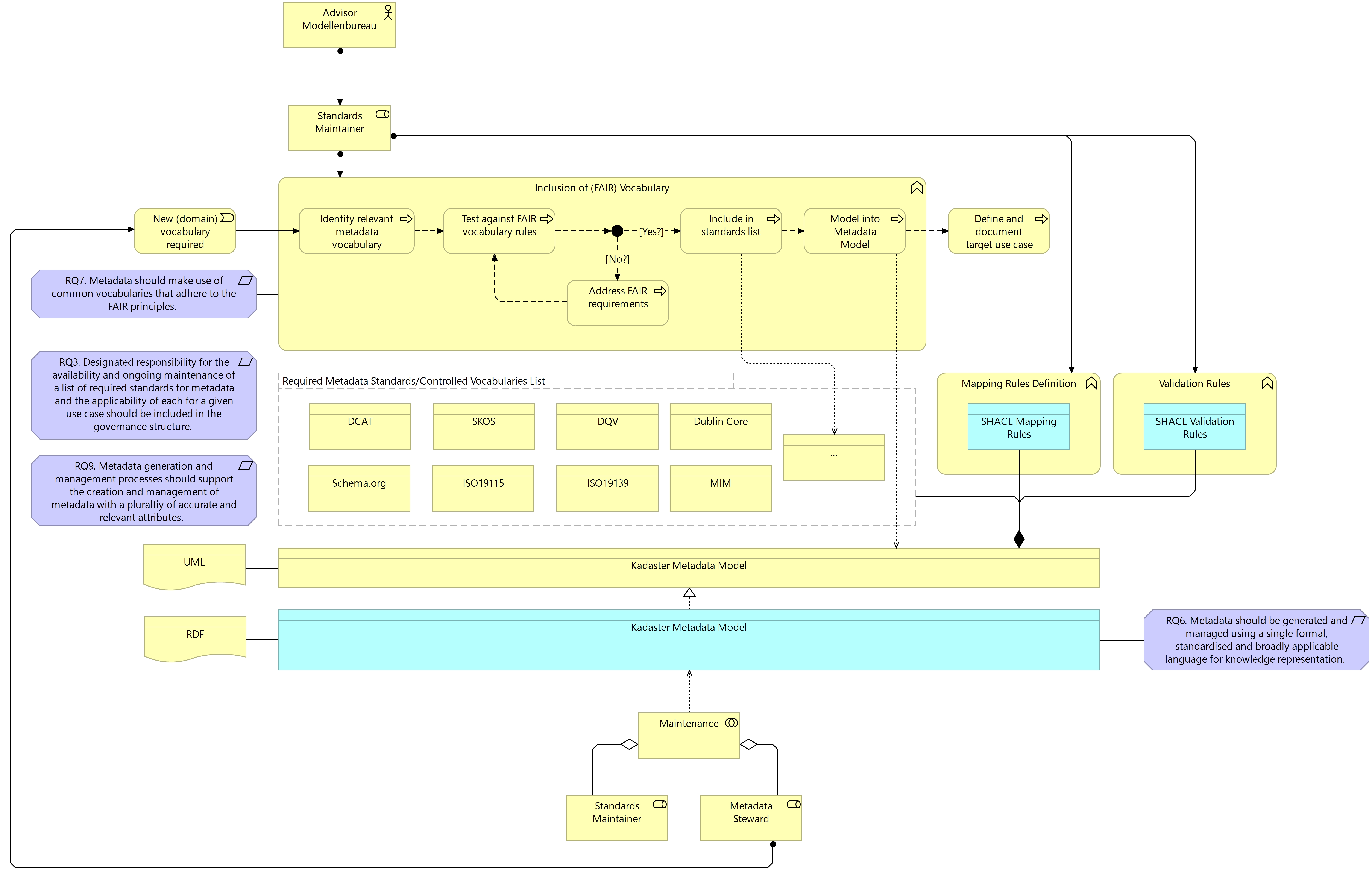
Interestingly, as the above rules highlight, the same governance process for external vocabularies can also be used for vocabularies and standards internally defined by Kadaster; supporting more consistency in the governance and quality of use standards and vocabularies within the organisation. Once included in the list of standards and vocabularies, the new addition needs to be accompanied by a specific use case description and needs to be modelled into the Kadaster Metadata Model, along with any relevant mapping and validation rules.
The above treatment design also highlights one of the more novel features of the treatment design; the introduction of the Kadaster Metadata Model defined for the management of metadata across the system as a whole. Although discussed in more detail in the following section, what the above architecture design illustrates is the fact that this metadata model is composed of various standards and vocabularies as well as mapping rules which implement the mapping of metadata from one standard to another where relevant in support of the generation of metadata for a specific use case. As a Kadaster-specific model for the management of metadata, the Modellenbureau is responsible for its maintenance. Support is likely to be required by stewards in implementing this model in a chosen management tool but will improve the quality of and efficiency with which metadata is managed across the organisation, in turn supporting better consistency across data assets.
Knowledge Language Representation
Much of the problem context analysis and the analysis of the baseline architecture highlights the need to move towards a more holistic, system-level approach to metadata management at Kadaster. This more centralised approach, as dictated by the system requirements, requires the addition of two things to the system architecture, namely; a standardised and broadly applicable language for knowledge representation that supports better interoperability of metadata across sub-systems and a centralised storage facility for metadata that is represented in this language. In support of the former, the treatment design for the system includes the definition of the Kadaster Metadata Model.
The Kadaster Metadata Model is a collection of relevant standards and vocabularies for representing metadata across all sub-systems. The Model in the business context is represented as a UML model and is operationalised as a RDF model in the application layer. RDF, therefore, is the chosen language for knowledge representation and, in addressing requirement 6, is standardised by the W3C and broadly applied as the language of choice for a number of the vocabularies documented in previous architecture models. Where relevant, the Model includes SHACL mapping rules based on the standard’s Advanced Features and SHACL validation rules based on SHACL shapes. SHACL is a shapes constraint language for describing and validating RDF graphs and is commonly used in the definition of linked data models and formalised ontologies (W3C, 2017).
Figure 7.9 (Repeat) Target System Architecture: Kadaster Metadata Model
The implementation of SHACL mapping rules supports automated mapping between metadata profiles where required, supporting stewards in generating metadata conforming to a single profile, mapping the same metadata to various metadata profiles and reusing this in a range of contexts. This process is discussed in more detail in the context of the dataset descriptions. SHACL validation rules, on the other hand, are defined to support the validation of generated metadata in conformance to the quality rules posed by a given outlet or in service of a given use case. These quality rules are defined as SHACL shapes and the structure of generated instance metadata is validated against these shapes.
The Kadaster Metadata Model is largely operationalised using SHACL mapping and validation rules rather than through the definition of a formalised ontology. Here, mapping rules formalise the association of related entitled across various standards or vocabularies. Where existing standards or vocabularies do not cover a specific use case, the model is simply expanded with new attributes and new mapping and validation rules constructed. This is done, in line with the general linked data design rules of reuse over new definition. With the flexibility offered by this approach, a range of standards and vocabularies are included in a single model, supporting greater plurality in the metadata available for a single data asset. The formalisation of these mapping rules also supports the formalisation of links between metadata resources across the organisation, allowing a dataset description to be related to a structural metadata record both on the level of shared attributes and on the level of the resource itself where no attributes are shared.
Ultimate responsibility for the maintenance of the Kadaster Metadata Model falls to the Modellenbureau in the role of the standard maintainer. However, as the role is assigned to the generation of requirements and quality rules for metadata, the maintenance of the model requires collaboration with metadata stewards in data asset teams. The initial definition of this model will likely require significant resources in the short term but, over time and as a consistent approach to metadata activities is taken across data asset teams, the maintenance of the model should not require significant resources; requiring an update only on the inclusion of a new standard, vocabulary or profile. Responsibility for identifying these new profiles largely falls to the stewards themselves based on their interaction with the publication outlets but may also be identified by the Modellenbureau based on their overarching role as the standards maintainer and in their collaboration with external standardisation entities such as Geonovum.
On implementation of the Kadaster Metadata Model, metadata activities across the system would be largely supported by linked data technologies. There are several benefits to this approach. Firstly, the use of these standardised technologies makes metadata across diverse sub-systems more interoperable and, therefore, easily integrated and reused in a variety of contexts. Seamless integration of different metadata resources supports better navigation between various sources of metadata offered by Kadaster, enabling richer and more comprehensive discovery of information. The use of these technologies in the metadata infrastructure, therefore, improves the FAIRness of metadata for internal stakeholders and, in turn, offers these stakeholders tools to improve the FAIRness of data for end users. Secondly, linked data’s triple-based structure provides flexibility and extensibility to the Model, supporting easy accommodation of new properties and relationships where a new use case arises without the need to change the existing schemas used. Indeed, the choice made to loosely couple existing vocabularies based on SHACL rules further strengthens the flexibility and extensibility of the model. In supporting such a large number of use cases in a single model, the generation of metadata need not focus on fulfilling the requirements of a single publication outlet but rather focus on generating a record which utilises the Model to its broadest extent. In addition, linked data technologies enable the use of semantic annotations in support of the addition of meaning and context to metadata. This promotes a better understanding of the metadata provided by both humans and machines as well as enables more intelligent data processing, search and inference opportunities in the future. Finally, publishing metadata as linked data aligns with the general principles of the Linked Open Data (LOD) movement which encourages the publication of data in open forms, using open standards and making this metadata available for anyone to access, reuse and contribute to. This increases the discoverability and visibility of metadata on the web, providing greater access to geospatial information.
Metadata Repository
In line with the system-wide approach offered by the introduction of the Kadaster Metadata Model, and in addressing the fourth system requirement, the target architecture system offers a design introducing a centralised metadata repository for the storage and management of all metadata within this system. This centralised repository aims to reduce the presence of the metadata siloes identified in the problem context by supporting better findability and integration of metadata within the Kadaster context. Indeed, metadata is no longer generated and stored in decentralised locations and made available only in specific publication outlets but is rather generated by stewards using the Kadaster Metadata Model, stored in the repository and accessed by many publication outlets. In support of the linked data approach taken in designing the Kadaster Metadata Model, the centralised repository takes the form of a triplestore which supports the creation of both linked data native endpoints and services such as SPARQL as well as more ‘mainstream’ endpoints and services such as GraphQL, ElasticSearch and other (geospatial) web services. The figure below (Figure 7.10) provides a system-level model, generalised for application across all sub-systems, showing the interaction of metadata activities in the business layer with the metadata repository and sub-system tooling in the application layer.
On the introduction of a new metadata record by a metadata steward, a new record is manually created in compliance with the relevant parts of the Kadaster Metadata model within a chosen sub-system tool. Once the record has been populated and validated in the sub-system tool by the relevant SHACL validation rules, the record is then uploaded to the metadata repository. On upload, the record is assigned a URI to ensure that all metadata records can be uniquely identified within the repository. Once a URI is assigned, a metadata graph is created and the service for the graph is started. For every new metadata record created, the steward can make the record available as a single resource with its endpoint or place the record in a collection of metadata graphs where the collection has a single endpoint. When a record is updated, the specific graph is accessed via the endpoint, updated through a SPARQL UPDATE query and the record is then versioned. This versioning rather than overwriting of metadata graphs supports the persistence of the metadata for a data asset across time.
Figure 7.10 Target System Architecture: Business Application Interaction
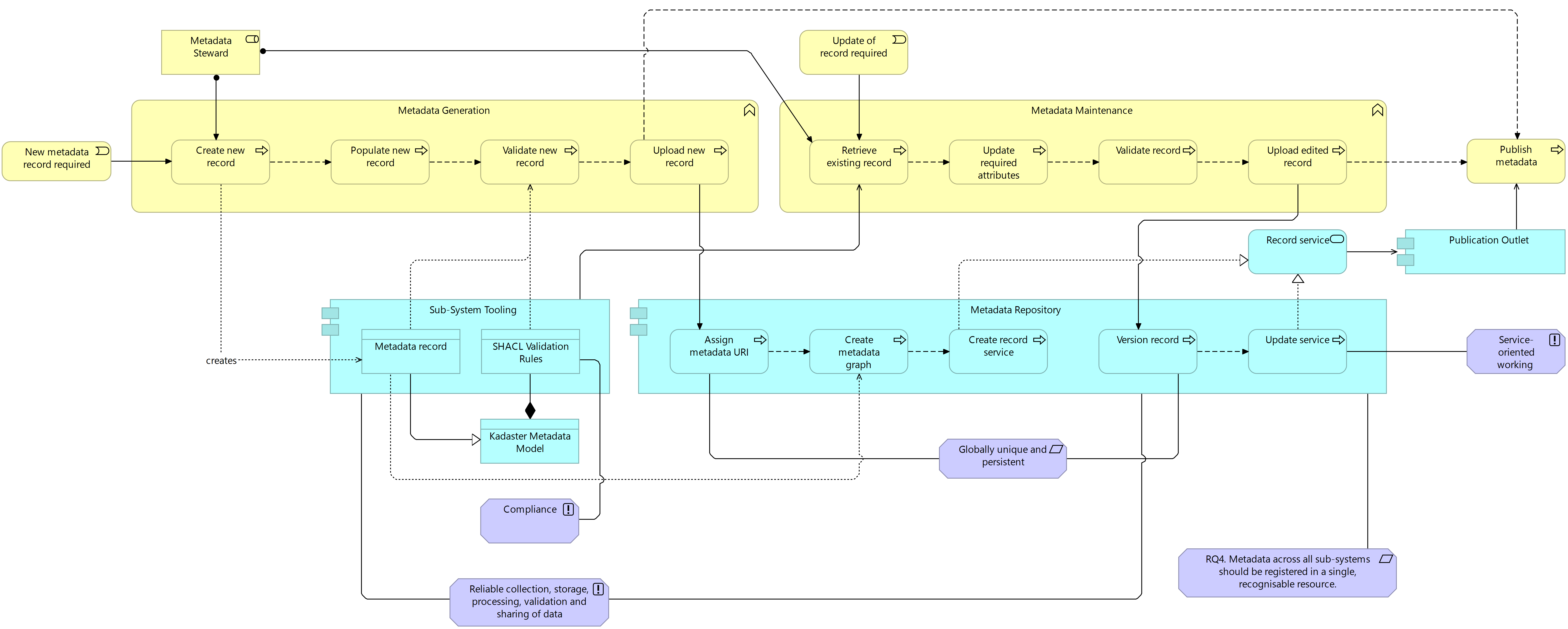
Publication outlets can be given access to the metadata stored in the repository in two ways, either through querying the SPARQL endpoint made available or based on a SPARQL Select Query which delivers a subset of the metadata defined in the query as a REST API. The latter approach can also be taken in defining a GraphQL endpoint for a graph or collection of graphs and defining a GraphQL API for use in a given publication outlet. The following figure formalised this description in the application architecture for the metadata repository.
Figure 7.11 Target System Architecture: Application Layer, Metadata Retrieval
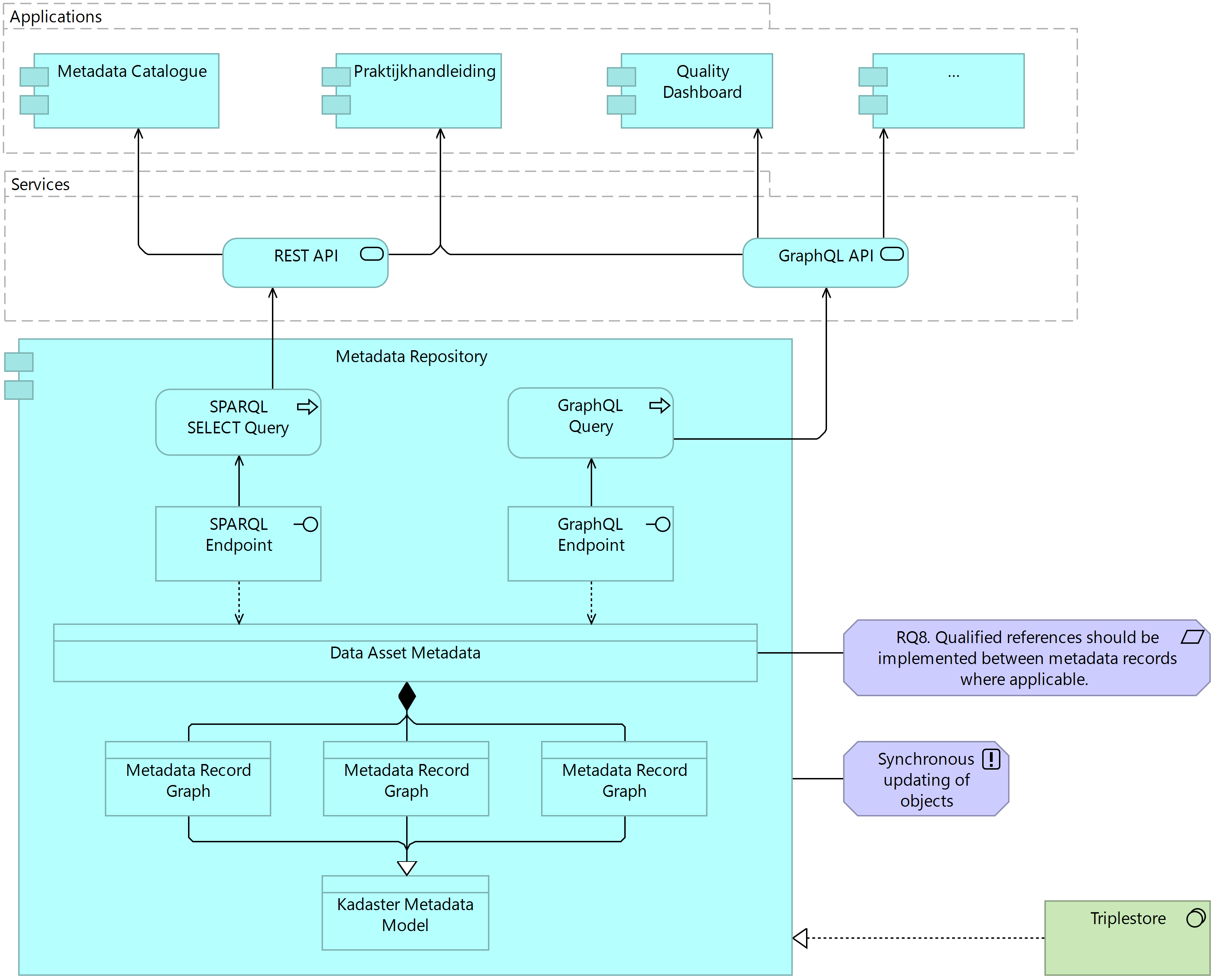
Important to note based on the above architecture is the ability to include formalised references between metadata records. These are made during the generation of metadata using the Kadaster Metadata Model and can, in turn, be queried for use in a given publication outlet. Although it is certainly possible for a steward to generate all metadata records serving the range of uses for a single asset by generating metadata conforming to the full scope of the Metadata Model, subsets or metadata records for different categories of metadata can be generated as individual graphs and combined in the triplestore as a complete metadata record. The definition of qualified references between metadata records serves to link these graphs together in the repository.
The graph approach depicted above offers the steward greater flexibility in the generation and maintenance of metadata for several resources. Firstly, the ability to create individual graphs for different categories of metadata allows the steward to make use of suitable tooling for the generation of specific metadata while still making this metadata centrally available. The use of specific tooling for specific categories of metadata is unlikely to be solved in practice. Indeed, the generation of structural metadata may be more suitable in VocBench while the generation of dataset descriptions is more suitable in a text editor the ability to combine these outputs based on a standardised language supports better integration of the metadata without needing to identify new tooling for generation. If these subsets reference each other, either through a formalised mapping or in the reuse of attributes, these metadata record graphs can be easily combined and traversed during querying in the repository. It should be noted, however, that the use of linked data technologies in the creation of these graphs also means that references between record graphs do not need to exist for graphs to be queried together. Secondly, the use of separate metadata record graphs for different categories of metadata makes the maintenance of metadata easier as a whole. Where a dataset description requires an update, this graph can be updated independently of the graph for other categories of metadata and, on upload, the metadata as a whole is updated.
The architecture illustrated above offers a service-oriented way of maintaining and publishing metadata in the Kadaster context. Indeed, the use of specific endpoints or APIs in publication outlets, rather than the management of data in application-dependent databases, allows updates to the metadata to be carried out completely independently of the Operational Teams responsible for the publication outlet. In addressing the fifth requirement, the service-oriented approach is supported by the use of standardised communications protocols used to connect the metadata repository to the publication outlet in question. An update to the service providing metadata to the application will automatically result in an update to the catalogue, dashboard or HTML page in question. This allows metadata to remain at the source, and a centralised source at that, while still ensuring the publication of quality metadata in publication outlets. This application independence also allows the metadata to remain persistent beyond the lifespan of the data it is documenting (in conformance with FAIR principle A2). The following figure provides an overview of the application architecture for the defined metadata repository. Here, each metadata graph is instantiated as a particular category of metadata and connected to the relevant tooling options identified by the baseline architecture. As such, the following architecture provides a target architecture for the system as a whole, rather than requiring the definition of individual architecture for each sub-system.
The flexibility now available to the system allows more user interfaces to be introduced and for the facilitation of exchange of metadata between repositories, enabling data integration and cooperation between a range of organisations and domains. Where a new use case for metadata publication is found, queries can be defined on the same endpoint made available to existing applications and the metadata need only be visualised accordingly in the publication outlet. In the list of end-user applications, the internal catalogue is introduced in support of the internal users of Kadaster’s metadata; both for the purpose of search and discovery of internal data products and services and for the findability of existing metadata for the purpose of reusing this in other contexts or publications. The inclusion of this internal catalogue, in providing a user interface for the metadata repository, truly supports the findability, accessibility and reusability of metadata by internal users in a standardised manner and thereby increasing the FAIRness of Kadaster’s data for external users.
Figure 7.12 Target System Architecture: Application Layer, Metadata Repository
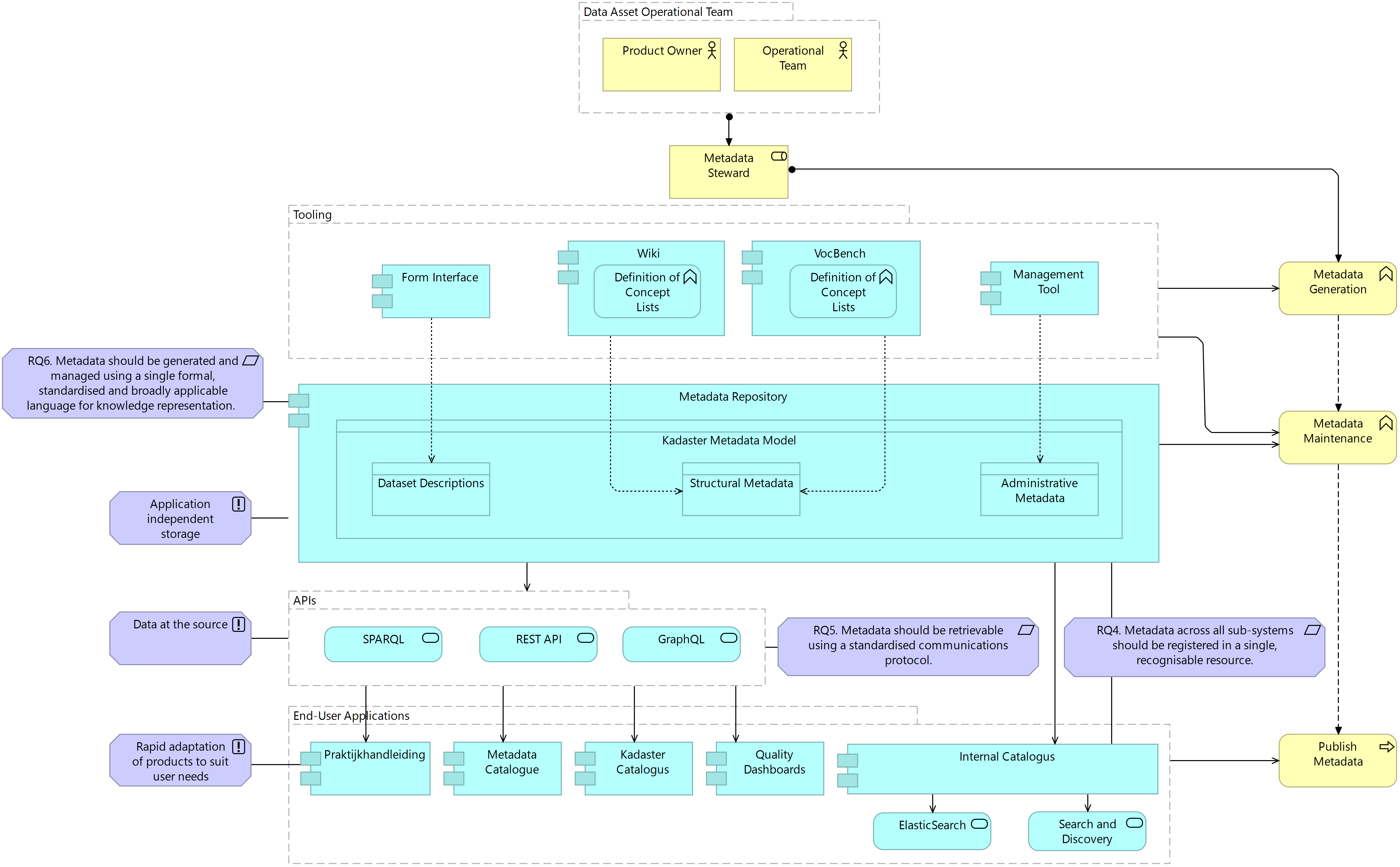
The inclusion of a centralised metadata repository in the target architecture also supports greater querying and analysis capabilities. A linked data repository facilitates advanced querying and analysis of metadata through SPARQL, allowing users to formulate complex queries to retrieve specific metadata based on various criteria and relationships. This enables detailed analysis, exploration and extraction of metadata insights, supporting tasks such as data profiling, statistics generation and knowledge discovery. Where greater analytical possibilities exist, there is greater potential for innovating how metadata is made available to end users but also how metadata is used in innovation projects going forward.
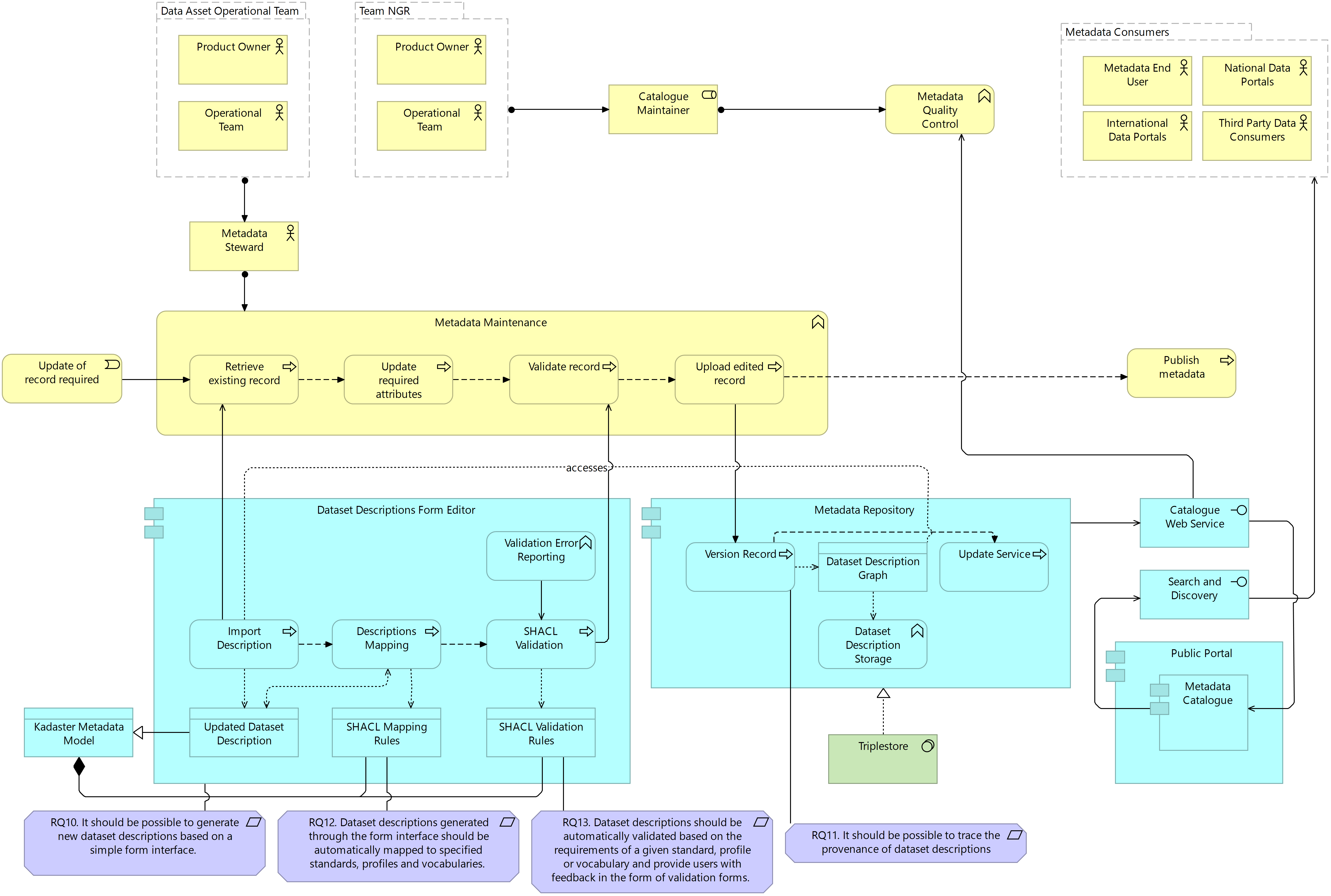
Dataset Descriptions Generation and Maintenance
Based on the problem context analysis and stakeholder interviews, two types of requirements were defined for the target architecture; those requirements targeted change on the level of the system as a whole and on the level of dataset descriptions specifically. While sub-system requirements were defined for the dataset description sub-system, no sub-system requirements were defined for the other two sub-systems. This was based on the fact that the system requirements address the challenges faced by stakeholders operating in the structural and administrative sub-system sufficiently. The treatment design based on the system requirements needed to be further refined in the context of the dataset description sub-system to address particular challenges faced by these stakeholders in carrying out metadata activities. It should be noted, however, that the sub-system requirements defined for dataset descriptions only represent refined versions of the system requirements. In addressing these sub-system requirements, therefore, the treatment designs for the dataset descriptions represent only refined versions of the system designs. No custom additions are made to the target system architecture to achieve these requirements.
The following treatment design presented all three architectural layers for the generation of dataset descriptions in the target architecture. As with the system architecture, a sub-system-specific tool in the form of a form editor interface supports the generation of dataset descriptions. This form editor is defined as a specific requirement in the treatment design due to the lack of existing tooling supporting the generation of quality dataset descriptions. The form is generated based on a vocabulary or standard as defined in the Kadaster Metadata Model. Once the form is populated by the steward, a mapping process is carried out by the application that supports the transformation of metadata from one standard, vocabulary or profile to another based on the mapping rules defined in the Model. Once the metadata has been mapped to all relevant dataset description profiles, a validation of the resulting metadata is carried out to ensure that both the input from the steward conforms to the quality rules defined as SHACL shapes and that mapping has resulted in valid metadata across all standards, vocabularies and profiles.
This mapping process, although technically implementable across the entire system based on the Kadaster Metadata Model, is particularly pertinent to the dataset descriptions sub-system where conformance to a range of standards and vocabularies (e.g. DCAT, schema.org, ISO19115) is required for a range of use cases (e.g. metadata catalogue interoperability, search indexability, INSPIRE compliance respectively). In addressing requirements 12 and 13, conformance to a range of standards, profiles and vocabularies is achieved based on a single input and validated according to the quality rules defined, supporting the generation of high-quality dataset descriptions efficiently. Once dataset descriptions are created, each can be uploaded as a single metadata record graph in the metadata repository following the assignment of a URI and queried alongside the structural and administrative metadata for use in a publication outlet.
Figure 7.13 Target Sub-System Architecture: Dataset Descriptions, Generation
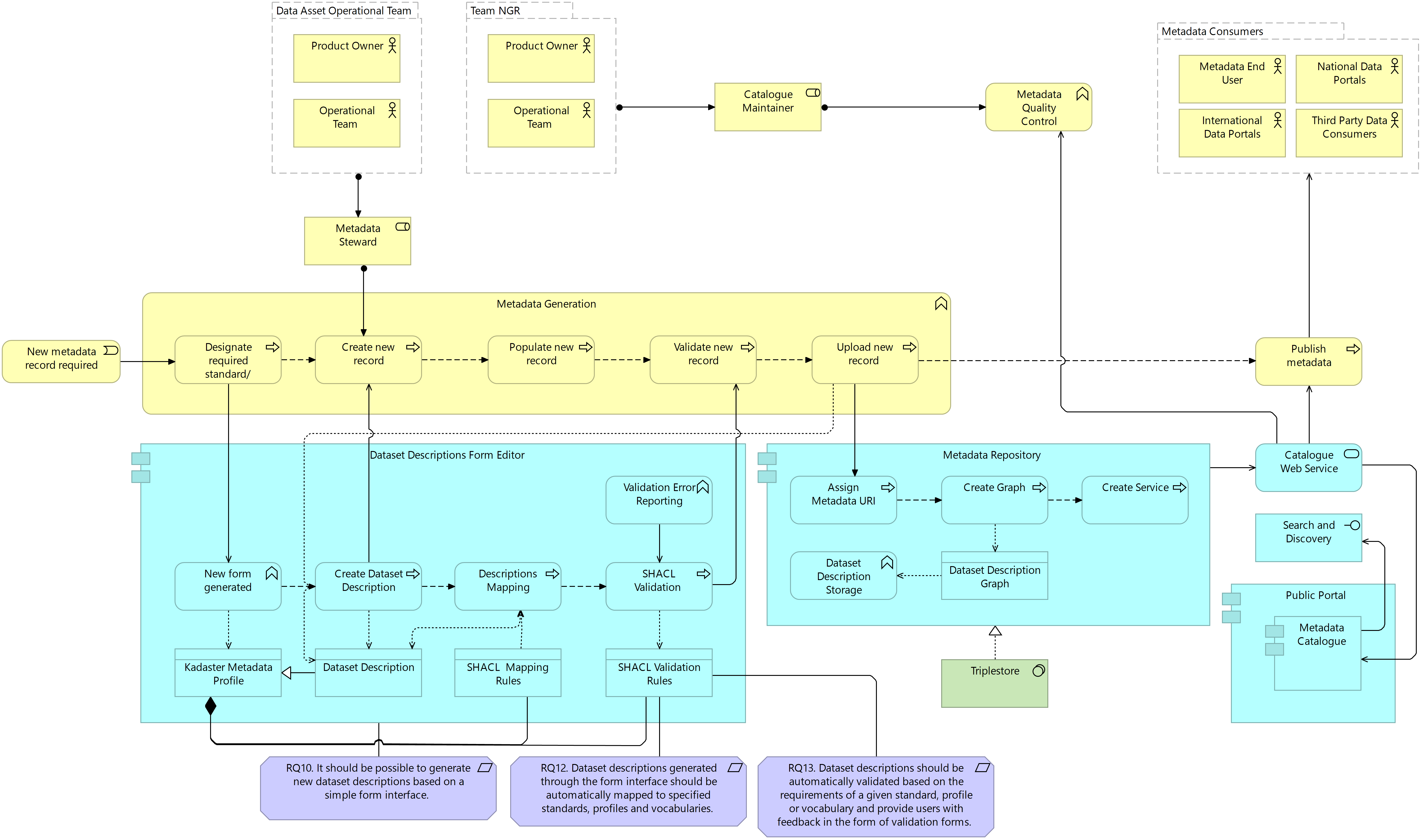
Dataset descriptions require a periodic update to reflect the updates made to the data assets and product themselves. It is, therefore, necessary that dataset descriptions can be versioned in an easy-to-use manner. The following figure illustrates the treatment design defined to support the ongoing maintenance of dataset descriptions. Here, an existing dataset description is retrieved from the metadata repository based on its unique identifier. The form interface initially populated by the steward is automatically populated with the existing information available in the metadata record. Changes can then be made to the form interface by the steward and, on completion, the mapping and validation process carried out for the updated dataset descriptions. Once mapped and validated, the resulting metadata record graphs are uploaded to the metadata repository. Rather than overwriting the existing metadata records with the updated record, the graph is versioned. In addressing requirement 11, this versioning includes information about the time of the last update to the graph, the information that was changed during the update and the steward responsible for the update itself. This offers the ability for metadata users to trace the provenance and lineage of metadata. Once the graph has been versioned, the service is updated and, where existing APIs are being accessed by publication outlets, dataset descriptions will be automatically updated in these outlets.
Figure 7.14 Target Sub-System Architecture: Dataset Descriptions, Maintenance