
Een validatiemethode van externe databronnen door middel van machine learning technieken
Introductie
De BRT is de naam van het product waar alle kaartinformatie in is opgeslagen van het Nederlandse grondgebied. Het Kadaster verzamelt, verwerkt en verstrekt topografische informatie op verschillende schalen voor de BRT van het Nederlandse grondgebied. Externe bronnen zoals het Centraal Bureau voor de Statistiek of De Dienst Uitvoering Onderwijs worden met name gebruikt voor het inwinnen en bijhouden van de gegevens in de volgende objectklassen:
- Gebouw
- Inrichtingselement
- Registratief gebied
- Geografisch gebied
- Plaats
- Functioneel gebied
Deze Use Case focust zich op de objectklasse ‘Gebouw’. Omdat de BRT onder andere essentieel is voor goede dienstverlening van de overheid, is het voor het Kadaster van groot belang dat de informatie in de BRT volledig, nauwkeurig en correct is. Voor het overgrote deel van de data is dit het geval. Echter zijn er gegevens die foutief of onbekend zijn of onwaarschijnlijke waarden bevatten. Het Kadaster streeft ernaar om zoveel mogelijk onbekende en foutieve gegevens aan te kunnen vullen om de kwaliteit van de data te verhogen. Daarnaast wil het Kadaster kosten besparen op inwinning van de data. Hierdoor is er een vraag naar het gebruik van community data zoals OpenStreetMap, een community-gedreven project dat uit onderzoek een relatief hoge nauwkeurigheid verstrekt ondanks dat de gegevens niet door opgeleide professionals zijn ingewonnen.
Momenteel wordt er bij de BRT weinig gebruik gemaakt van community data bij het inwinnen van gebouwtypes. Het is daarom bij het Kadaster niet bekend hoeveel waarde die externe bronnen kunnen hebben. Vaak zijn bijdragers van community data geen opgeleide professionals. Hierdoor is de kwaliteit van de gegevens niet gegarandeerd door het inwinningsproces van bijdragers. Extra aandacht is er daarom nodig bij het valideren van de externe bronnen. Om die reden is een methode ontwikkeld die externe bronnen valideert door middel van machine learning technieken. Voor een uitgebreid verhaal over hoe de validatiemethode ontwikkeld is nodigen we de lezer uit om deze Use Case verder te lezen.
Aanpak
De ontwikkelde validatiemethode bestaat uit het classificeren van een gebouwtype aan de hand van straatfoto’s door middel van een Convolutioneel Neuraal Netwerk model. De structuur van het onderzoek en de stappen die worden genomen worden afgebeeld in figuur 1.
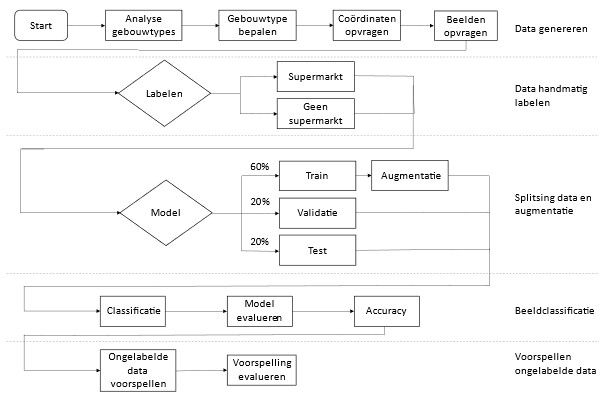
Data genereren
Een vereiste bij het kiezen van een gebouwtype uit OpenStreetMap (OSM) voor de validatiemethode is dat het gebouwtype veel opgenomen objecten moet bevatten. Dit is belangrijk voor het trainen van een neuraal netwerk model. Daarnaast is het ook belangrijk dat het gebouwtype unieke fysieke kenmerken heeft die herkenbaar zijn voor dat specifieke gebouwtype. Dit is belangrijk voor het model om patronen te identificeren tussen alle foto’s voor mogelijk een hoger nauwkeurigheid leveren bij het trainen, valideren en testen van het model. Een gebouwtype uit OSM die veel objecten bevat en fysieke kenmerken heeft is het gebouwtype ‘supermarkt’. OSM heeft 4802 supermarkten opgenomen wat een goede grootte kan zijn voor een trainen, valideren en testen van een neuraal netwerk model. Daarnaast zijn supermarkten van de buitenkant vaak te herkennen (logo, naam, schappen binnen die van buiten zichtbaar zijn, winkelwagens of reclameborden). Daarom wordt het gebouwtype ‘supermarkt’ uit OSM toegepast in de validatiemethode.
De straatfoto’s van supermarkten halen we op via Cyclomedia en gebruiken we bij het trainen en testen van het model. Aan de hand van coördinaten kunnen we alle straatfoto’s opvragen via Street Smart: Interactieve web viewer voor alle Cyclomedia-data. Via databaseserver PostgreSQL zijn de meest recente data van OpenStreetMap beschikbaar. Door middel van een SQL code vragen we alle coördinaten van supermarkten op. Door alle coördinaten onder elkaar in een txt bestand in te laden op Street Smart, worden alle straatfoto’s onder elkaar in een afspeellijst weergegeven. Die straatfoto’s halen we automatisch op door middel van een Python script. Zo zijn er uiteindelijk 4542 foto’s van supermarkten opgehaald.
Data handmatig labelen
Een gedeelte van de straatbeelden labelen we vervolgens in 2 klassen; 1 – supermarkt; 2 geen supermarkt. In figuur 2 is een overzicht weergegeven van verschillende straatfoto’s per klasse. De straatfoto’s, waarvan duidelijk te zien is dat het een supermarkt is zoals een foto van de ingang of waar het logo of naam duidelijk in beeld is, labelen we in de klasse ‘supermarkt’. Foto’s waarvan het minder duidelijk is of het een supermarkt is zoals de achterkant van het gebouw of waar een grote vrachtwagen voor staat, labelen we in de klasse ‘geen supermarkt. Uiteindelijk bestaat de gelabelde dataset uit 1800 foto’s uit de klasse ‘supermarkt’, 429 foto’s uit de klasse ‘geen supermarkt’ en vullen we de klasse aan met 1371 foto’s van andere gebouwtypes.

Splitsing data en augmentatie
De gelabelde dataset splitsen we vervolgens in 3 sets:
- Trainset
- Validatieset
- Testset
Om het aantal gelabelde foto’s in de trainset te verhogen, maken we gebruik van data augmentatie. Data augmentatie is een techniek die gebruikt wordt om de dataset te vergroten voor het trainen van het model zonder daadwerkelijk nieuwe data te verzamelen. Augmentatie technieken zoals inzoomen, herschalen, roteren en verschuiven zijn toegepast op de beelden die gebruikt zijn voor het trainen van het model. In figuur 3 is weergegeven hoe de data augmentatie strategie voor de traindataset eruit ziet. Uiteindelijk bestaat de traindataset uit 4200 foto’s per klasse, validatieset uit 360 foto’s per klasse en de testset uit 360 foto’s per klasse.

Beeldclassificatie
In deze Use Case gebruiken ontwikkelen we 3 modellen met verschillende architecturen voor het trainen, valideren en testen. Omdat de testdataset een zuivere schatting geeft van de prestaties van het eindmodel, vergelijken we de modellen door middel van de accuracy van de testdataset. Het model met de beste accuracy op de testdataset, zal antwoord geven op in hoeverre het mogelijk is om supermarkten te herkennen door middel van machine learning technieken.
Voorspellen ongelabelde data
Daarnaast zal het beste model uitgevoerd worden om de overige ongelabelde supermarkt straatbeelden te voorspellen. Hieruit zal de verhouding tussen de twee klassen van het gebouwtype geëvalueerd worden. Om de kwaliteit van de externe community databron (OpenStreetMap) voor de supermarkten te bepalen vergelijken wij het aantal grote supermarkten uit OSM met het aantal grote supermarkten uit externe bron Aanbiedingenfolders. Aanbiedingenfolders is een website waar de meest recente folders van de grote supermarkten in Nederland beschikbaar is. Daarnaast biedt Aanbiedingenfolders ook de adressen van de alle grote supermarkten. Dit zijn er volgens Aanbiedingenfolders 4133. De straatfoto’s van de adressen uit Aanbiedingenfolders worden op dezelfde manier opgehaald als de foto’s uit OSM. Het beste model zal uiteraard ook uitgevoerd worden om de straatfoto’s van Aanbiedingenfolders te voorspellen.
Resultaten
Na het analyseren van het probleem, verkrijgen van de data en het ontwikkelen van een methode, kunnen we de classificatiemodellen ontwikkelen. Uit de ontwikkelde modellen, is er 1 model dat het beste presteert. Het beste model is hieronder weergegeven.
Het beste model
Het beste model is gebaseerd op de Convolutioneel Neuraal Netwerk (CNN) tutorial van TensorFlow waarbij enkele aanpassingen zijn gemaakt. In de figuur 4a & b is de prestatie van het model geëvalueerd.
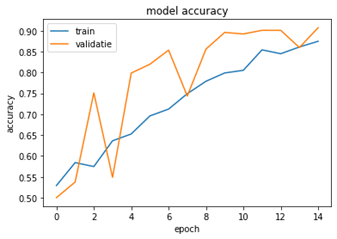
Zoals te zien is in figuur 14a, stijgt de accuracy van de trainingsdata geleidelijk over de 15 epochs en blijft de curve ook stijgen. Hoewel de curve in dit model blijft stijgen en niet vlakker wordt, heeft het verhogen van de epochs geresulteerd tot overfitting. Net als de accuracy grafiek uit model 1, is de accuracy curve van de validatiedata hoger dan de accuracy van de trainingsdata. Wat wel opvalt is dat de curve van de validatiedata fluctueert over de epochs heen. Een verklaring hiervoor kan zijn dat de grootte van de validatie set te klein is, dit kan resulteren in het schommelen van de validatie accuracy. Dit kan voor deze Use Case het geval zijn aangezien de verhouding tussen de trainingsdata en validatiedata groot is (91,4% train vs. 4,3% validatie). Dit heeft over het algemeen geen invloed op de prestaties van het model als de accuracy curve van de validatiedata mee stijgt met de curve van de trainingsdata.
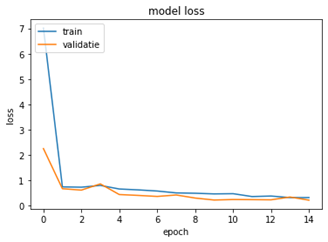
Aan de hand van de grafiek is te zien dat de loss van de trainingsdata geleidelijk daalt naar een punt en vervolgens stabiliseert. Daarnaast daalt de loss curve van de validatiedata mee en is er weinig ruimte tussen de twee loss waardes. Dit betekent dat het model niet overfit is.
Dit model is ook uitgevoerd op de testdata. Aan de hand van de accuracy van de testdata, heeft het model een accuracy bereikt van 88,89% (tabel 1). De accuracy van het model geeft aan dat het een uitstekend model is voor het classificeren van het gebouwtype ‘supermarkten’ omdat het percentage tussen 80% en 90% ligt.
| Fase | Accuracy |
|---|---|
| Train | 90,74 |
| Validatie | 90,75 |
| Test | 88,89 |
Tabel 1: Classificatie accuracy van het beste model
Classificeren van de ongelabelde straatbeelden
OpenStreetMap
Vervolgens gebruiken we het beste model om de ongelabelde straatbeelden van supermarkten te classificeren. Uit de 2313 ongelabelde beelden voorspelt het model dat 645 foto’s bij de klasse ‘Supermarkt’ horen en 1668 foto’s bij ‘Geen supermarkt’. In tabel 2 is een overzicht weergegeven met het aantal gelabelde en ongelabelde foto’s per klasse.
| Klasse | Aantal gelabelde foto’s | Aantal ongelabelde foto’s | Totaal |
|---|---|---|---|
| Supermarkt | 1800 | 645 | 2445 |
| Geen supermarkt | 429 | 1668 | 2097 |
Tabel 2: Het aantal gelabelde en ongelabelde foto’s voor de klasse ‘Supermarkt’ en ‘Geen supermarkt.’
Vervolgens controleren we alle ongelabelde foto’s uit klasse ‘Geen supermarkt’. Het volledige overzicht van de aantallen is in tabel 3 weergegeven.
| Klasse | Totaal |
|---|---|
| Supermarkt | 2194 |
| Geen supermarkt | 1129 |
| Slechte hoek of supermarkt | 1001 |
Tabel 3: Volledige overzicht van de straatfoto’s per klasse (OSM).
Zo zijn er na het handmatig controleren van de ongelabelde niet supermarkten, 2194 foto’s uit de klasse ‘supermarkt’ waarvan wij zeker weten dat het een supermarkt is, 1129 foto’s uit ‘geen supermarkt’ waarvan wij zeker weten dat het geen supermarkt is, en 1001 foto’s van slechte hoeken of supermarkten die in de verkeerde klasse is geclassificeerd.
Aanbiedingenfolders
Ten slotte gebruiken we het best presterende model om de opgehaalde straatfoto’s uit Aanbiedingenfolders te classificeren. Van de 3885 straatfoto’s zijn er 2575 foto’s in de klasse ‘supermarkt’ geclassificeerd en de overige 1310 foto’s bevinden zich in de klasse ‘geen supermarkt’. Na het handmatig controleren zijn we tot conclusie gekomen dat er 2494 foto’s uit de klasse ‘supermarkt’ waarvan wij zeker weten dat het een supermarkt is, 128 foto’s uit ‘geen supermarkt’ waarvan wij zeker weten dat het geen supermarkt is, en 1263 foto’s van slechte hoeken of supermarkten die in de verkeerde klasse is geclassificeerd. Het volledige overzicht van de aantallen is in tabel 4 weergegeven.
| Klasse | Totaal |
|---|---|
| Supermarkt | 2494 |
| Geen supermarkt | 128 |
| Slechte hoek of supermarkt | 1263 |
Tabel 4: Volledige overzicht van de straatfoto’s per klasse (Aanbiedingenfolders).
Realisatie
Na het vergelijken van de aantallen tussen tabel 3 en 4 valt op dat er meer supermarkten geclassificeerd zijn in Aanbiedingenfolders dan in OSM. Daarnaast heeft Aanbiedingenfolders ook meer foto’s van slechte hoeken of supermarkten die verkeerd zijn geclassificeerd. Om te concluderen of Aanbiedingenfolders tot een hogere kwaliteit beschikt dan OpenStreetMap, zal de slechte hoek foto’s gecontroleerd moeten worden om te bepalen of het wel of geen supermarkt is. Daarnaast moet het aantal supermarkten die in de verkeerde klasse zijn geclassificeerd opgeteld worden en in de juiste klasse worden toegevoegd. Voor OSM zijn het 1001 foto’s die handmatig gecontroleerd moeten worden en voor Aanbiedingenfolders zijn het 1263 foto’s. In het vervolgonderzoek adviseren we om de bovengenoemde punten uit te voeren om de kwaliteit van de supermarkten uit OSM en Aanbiedingenfolders te kunnen bepalen.
Conclusie
De resultaten van de ontwikkelde modellen laten zien dat deep learning technieken goed werken op het classificeren van het gebouwtype ‘supermarkt’. Het beste model heeft een accuracy bereikt van 90%. Echter laten de plots zien dat de modellen mogelijk nog beter kan presteren. In het vervolgonderzoek adviseren we om de modellen te finetunen voor betere prestaties.
De kwaliteit van de externe bronnen die zijn gebruikt kan niet worden bepaald doordat er nog straatfoto’s zijn die handmatig gecontroleerd moeten worden. In het vervolgonderzoek kan de kwaliteit van de externe databron bepaald worden door, de straatfoto’s uit een slechte hoek of foto’s die verkeerd zijn geclassificeerd, handmatig te controleren om de beelden in de juiste klasse te plaatsen.
Hoe goed de validatiemethode werkt hangt af van een aantal factoren. De eerste factor is of het gebouwtype unieke fysieke kenmerken heeft die herkenbaar zijn voor dat specifieke gebouwtype. De tweede factor is om veel objecten te hebben van het gebouwtype voor het trainen van een classificatiemodel. Tot slot hangt de validatiemethode van de bereikbaarheid voor de Cyclomedia auto af. Het gebouwtype moet over het algemeen makkelijk bereikbaar zijn met een auto, zodat de straatfoto’s vanuit de goede kant genomen kan worden. Ondanks de beperkingen van de straatfoto’s die via Cyclomedia zijn opgehaald, heeft deze Use Case laten zien dat er potentie is in het gebruik van machine learning technieken voor het valideren externe databronnen.