Introductie
Binnen de directie BOI willen we meer datagestuurd gaan werken. Dit houdt in dat we data meer als uitgangspunt gebruiken om onze taken te besturen en verantwoorden. Dit kan tevens bijdragen aan een hogere voorspelbaarheid. Hiervoor is het nodig om de bedrijfsvoering data te combineren, toegankelijk, inzichtelijk en bruikbaar te maken en te analyseren zodat hierop geanticipeerd kan worden. Een ontwikkeling waarbij Kadaster in de toekomst kan anticiperen op zaken als bijvoorbeeld een te hoge werkdruk in de teams, onvoorziene incidenten of te hoge kosten.
Met het Emerging Technology Center (ETC) en Data Science Team (DST) gaan wij BOI ondersteunen in deze ambities. Dit bestaat uit het aanbieden van handvatten en inzichten aan teams, waaruit zij haar eigen conclusies kunnen trekken. Dit is tevens bedoeld om te bepalen wat er noodzakelijk is om de volgende stap naar productie te brengen.
Aanpak
De eerste fase heeft als doel om de wensen en behoeften op te halen bij onze verschillende doelgroepen, de teams zelf tot en met het management. Daarnaast zal er inzichtelijk worden gemaakt welke hulpmiddelen al bestaan binnen Kadaster, welke brondata hierachter zit en welke data er nog mist.
De volgende stap zal in het teken staan van het centraliseren en combineren van deze brondata, waarop het DataScienceTeam vervolgens analyses, zoals trends en correlaties, kan uitvoeren. Het doel is om de uitkomsten van deze analyses zo goed mogelijk aan te sluiten op de behoeften van de eindgebruikers. Op deze manier wordt de bruikbaarheid voor deze groep veiliggesteld. Hiervoor zal ook de aansluiting gezocht worden met bestaande dashboards en KPI’s.
De uitkomsten zullen inzichtelijk gemaakt worden in vernieuwde dashboards waarop de desbetreffende teams zelf kunnen sturen waar nodig en waarbij de samenhang tussen diverse processen ook duidelijk wordt. Het uiteindelijke doel is om dit op de juiste manier te laten landen binnen de teams, waarbij dit wordt geadopteerd als een hulpmiddel om beter voorspelbaar te zijn.
Status data centraliseren, combineren en visualiseren
Naast het inventarisen van de wensen en behoeften bij de doelgroepen is er een start gemaakt aan het centraliseren, combineren en visualiseren van data. Het doel is om de technische haalbaarheid te onderzoeken en de uitdagingen te vinden. Er is begonnen met het ontsluiten van één bron: JIRA. Het is gelukt om met de JIRA API de data te extracten. Dit gebeurd met een python script, welke de data in een (PostgreSQL) database plaatst. Met behulp van andere python scripts wordt vervolgens de data binnen de database gecombineerd, getransformeerd en geanalyseerd.
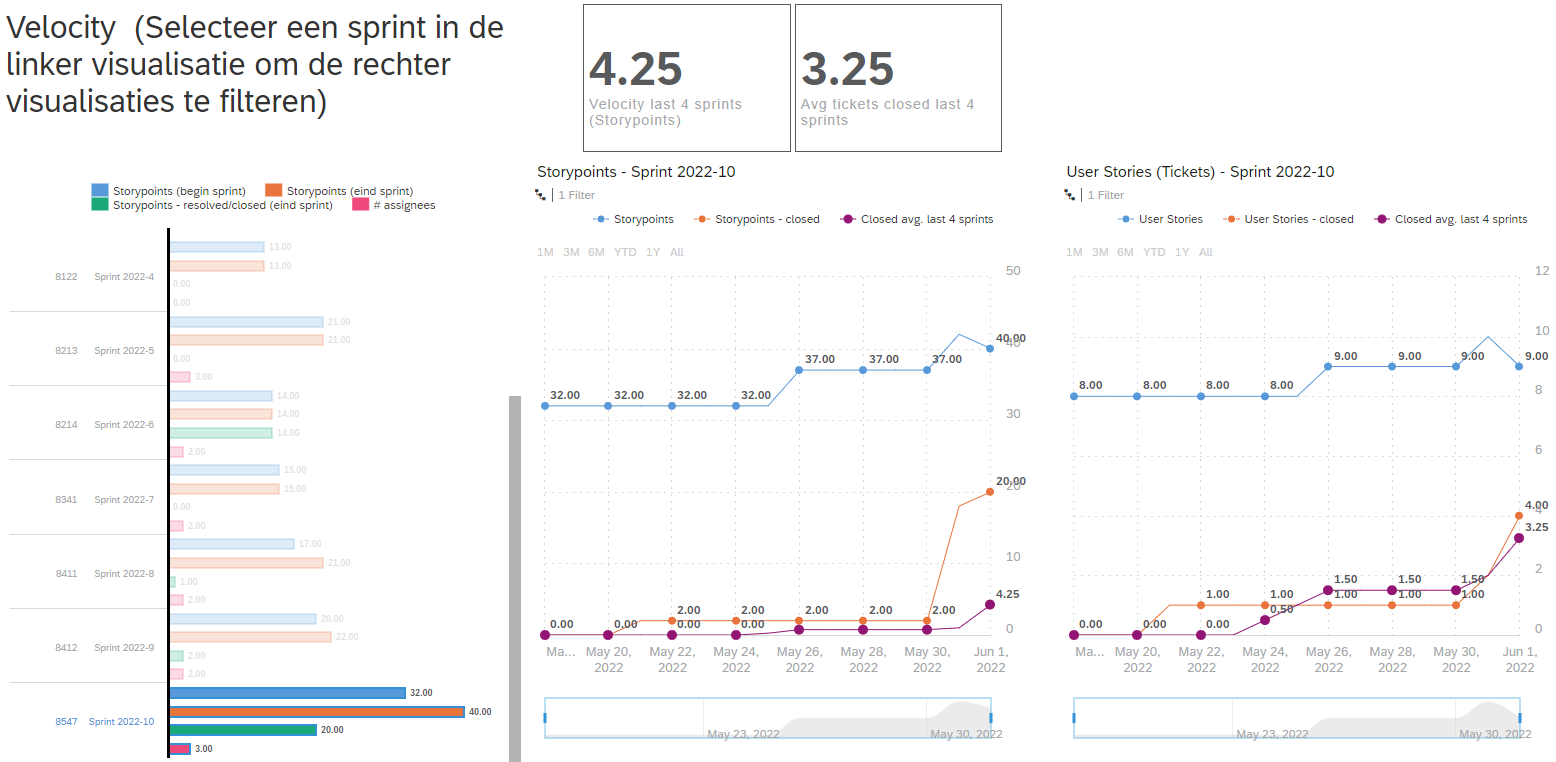
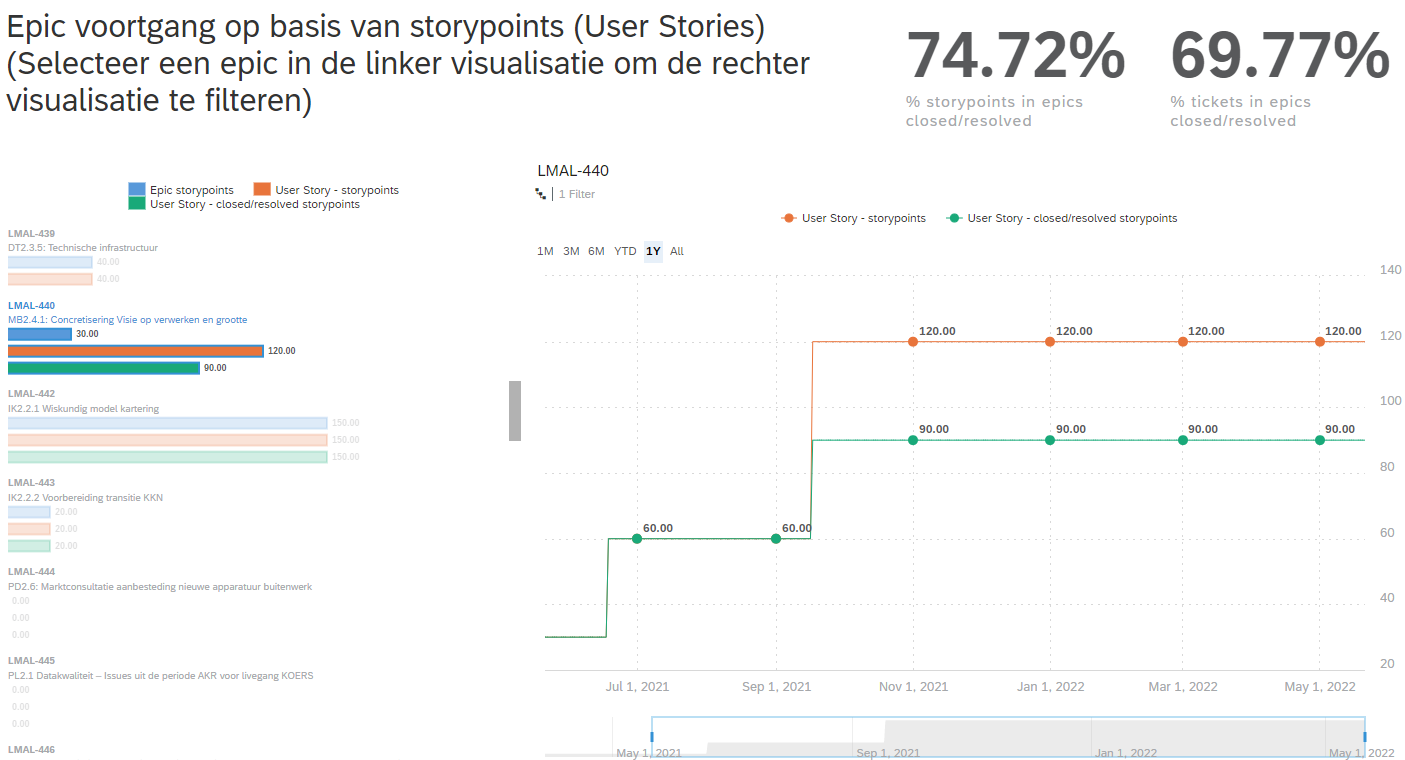
De tool ‘SAP analytics cloud’ is gebruikt om de JIRA data uit de database te visualiseren. Onderstaand zijn enkele screenshots uit een eerste opzet binnen SAP analytics cloud (nog niet overlegd met gebruikers).
Screenshots SAP analytics cloud dashboard